У овој секцији упознаћемо нешто детаљније скуп података ЕurLex57k.
Скуп података ЕurLex57k је представљен на конференцији ACL 2019. године у раду
Ilias Chalkidis et. al: Large-Scale Multi-Label Text Classification on EU Legislation
Рад је доступан на овој адреси.
Скуп података EurLex57k представља колекцију од 57 хиљада докумената преузетих са платформе EUR-lex . Платформа EUR-lex је централна платформа преко које се са јавношћу деле званични документи Европске уније попут закона, међународних споразума, судских пракси, националних мера транспозиције и многих других типова правних докумената. Сваки од ових докумената је доступан на 24 званична језика Европске уније, али скуп података EurLex57k обједињује само верзије ових докумената на енглеском језику.
Сваки документ скупа података EurLex57k има свој јединствени идентификатор, такозвани CELEX број. CELEX број се састоји из 4 дела: назнаке сектора којем документ припада, четвороцифрене године објављивања документа, дескриптора документа и броја документа. Сектора има укупно 12 и обележавају се бројевима од 0 до 9 или латиничним словима C и Е. Тако, на пример, сектору 9 припадају документа која се односе на парламентарна питања, а сектору 4 документа комплементарног законодавства. Дескриптор документа се састоји од једног или два слова са предефинисаним значењем. На пример, латинично слово L се односи на директиве, латинично слово R на регулативе, а латинично слово D на одлуке. Број документа се записује као четвороцифрени број и представља званични број, интерни број или датум публиковања. Постоје и нека одступања од ових правила именовања условљена верзионисањима и коректурама докумената. Више о CELEX бројевима се може прочитати на званичној страници EUR-Lex платформе.
Документи се састоје од заглавља које садржи наслов и име регулаторног тела, рецитала и тела документа које је најчешће организовано по члановима. На овој адреси можете видети пример једног документа EurLex57k колекције - Опште регулативе о заштити података (енгл. General Data Protection Regulation) којој одговара CELEX број 32016R0679.
Да бисмо учитали скуп података EurLex57k искористићемо функцију loda_dataset пакет datasets библиотеке transformers. Довољно је да приликом њеног позива наведемо аргумент eurlex.
from datasets import load_dataset
dataset = load_dataset('eurlex')
Учитани скуп података, попут других скупова који су припремљени за задатке машинског учења, садржи скуп за обучавање (енгл. training set), скуп за валидацију (енгл. validation set) и скуп за тестирање (енгл. test set). Подсетимо се да се скуп за обучавање користи за креирање модела, скуп за валидацију за одређивање вредности метапараметара модела и праћење тока обучавања, док се скуп за тестирање користи за оцену квалитета наученог модела. Сваки од ових скупова података можемо издвојити из учитаног скупа dataset коришћењем назнака скупа train, validation или test.
train_data = dataset['train']
validation_data = dataset['validation']
test_data = dataset['test']
За анализирање скупа докумената искористићемо скуп за обучавање train_data који ћемо због лакше манипулације трансформисати у структуру DataFrame пакета Pandas.
import pandas as pd
train_data_pd = pd.DataFrame(train_data)
Сада можемо проверити колико докумената садржи скуп за тренирање. Подсетимо се, у томе нам може помоћи својство shape.
train_data_pd.shape
Скуп за тренирање садржи 45 хиљада докумената, а можемо видети да се сваки од докумената описује са 4 атрибута. Истражимо о којим атрибутима је реч тако што ћемо прочитати имена колона скупа за тренирање. Можемо искористити својство columns.
train_data_pd.columns
У питању су атрибути celex_id, title, text и eurovoc_concepts. Атрибут celex_id представља поменути јединствени CELEX број документа. Атрибут title садржи наслов документа, а атрибут text његов садржај. Атрибут eurovoc_concepts представља низ мануелно придружених лабела-концепата које одређују категорије којима документ припада. Пре него ли детаљније упознамо смисао ових лабела, издвојимо један насумичан документ скупа и његове атрибуте. На пример, можемо издвојити документ који се налази на 15. позицији у скупy (опрез: нумерација у програмским језицима најчешће почиње од нуле!).
example_index = 14
train_document_example = train_data_pd.iloc[example_index]
CELEX broj:
train_document_example['celex_id']
Naslov dokumenta:
train_document_example['title']
Sadržaj dokumenta (prvih 500 karaktera):
train_document_example['text'][:500]
EuroVoc labele dokumenta:
train_document_example['eurovoc_concepts']
Да би колекција докумената којом располаже Европска унија могла систематично да се организује, одржава и претражује, сваком од докумената је мануелно придружено неколико лабела које одређују којим то категоријама документ припада. За те сврхе је од стране Европске уније креиран и попис свих релевантних одредница, такозвани терминолошки речник или тезаурус, који се зове EuroVoc. Овај тезаурус покрива све сегменте деловања Европске уније (политику, међународне односе, економију, образовање, науку, агрикултуру, итд.) и тренутно садржи 7, 201 лабела-одредница на свим званичним језицима Европске уније и, додатно, за албански, македонски и српски језик. На званичној адреси се може прочитати више о самом тезаурусу, кaо и начини претраживања колекција докумената у складу са овако дефинисаним одредницама.
Да бисмо истражили организацију EuroVoc теазауруса и разумели значење одредница које су придружене нашем документу, преузели смо верзију тезауруса у формату JSONL са ове адресе и сачували је под именом eurovoc_concepts.jsonl у директоријуму data. Следећа функција eurovoc_from_jsonl_to_pd ће нам помоћи да на основу ове датотеке креирамо структуру DataFrame која омогућава лакши рад.
Формат датотеке JSONL (енгл. JSON line) представља формат датотеке у којем је свака линија записана у JSON формату. Овај формат сте упознали у уводној секцији о програмском језику Python.
import json
def eurovoc_from_jsonl_to_pd(path='data/eurovoc_concepts.jsonl'):
# kreiramo strukturu DataFrame u koju cemo smestiti identifikatore i imena koncepata
eurovoc_concepts_pd = pd.DataFrame(columns={'id', 'title'})
# pripremamo datoteku za citanje
with open(path, 'r') as eurovoc_file:
# citamo liniju po liniju datoteke
for eurovoc_line in eurovoc_file.readlines():
# procitanu liniju prebacujemo iz JSON formata u recnik
eurovoc_concept = json.loads(eurovoc_line)
# dodajemo red sa odgovarajucim podacima recnika kreiranoj DataFrame strukturi
eurovoc_concepts_pd = eurovoc_concepts_pd.append({
'id': eurovoc_concept['id'],
'title': eurovoc_concept['title']
}, ignore_index=True)
# kreiranu i popunjenu strukturu vracamo kao rezultat funkcije
return eurovoc_concepts_pd
eurovoc_pd = eurovoc_from_jsonl_to_pd()
Пре свега, можемо потврдити да тезаурус EuroVoc садржи јако велики број лабела-одредница, чак 7, 201!
eurovoc_pd.shape
Првих 10 одредница тезауруса можемо прочитати користећи функцију head са аргументом 10.
eurovoc_pd.head(10)
Kао што смо очекивали свака лабела-одредница има свој јединствени идентификатор представљен атрибутом id и своје име представљено атрибутом title.
Пример документа из скупа за обучавање је имао придружене лабеле-одреднице чији су идентификатори ['1309', '2300', '3591', '5034'], па сада можемо видети и о којим одредницама је реч. Техничка напомена је да се у структури eurovoc_pd идентификатори представљају као ниске, чак и ако не видимо наводнике око њих (ова тврдња се може проверити извршавањем функције eurovoc_pd.info() и праћењем типова колона).
eurovoc_pd[eurovoc_pd['id'].isin(['1309', '2300', '3591', '5034'])]['title']
Пошто ће нам очитавање имена одредница често бити потребно, можемо написати и функцију која за задати низ идентификатора одредница враћа листу њихових имена.
def concept_names(eurovoc_pd, eurovoc_concepts_ids):
return eurovoc_pd[eurovoc_pd['id'].isin(eurovoc_concepts_ids)]['title'].values.tolist()
Проверимо још једном како изгледа резултат позива функције на примеру документа из скупа за обучавање.
concept_names(eurovoc_pd, train_document_example['eurovoc_concepts'])
Даље можемо истражити колико концепата-лабела у просеку имамо по документу у скупу за обучавање.
number_of_concepts_per_document = train_data_pd['eurovoc_concepts'].apply(lambda concepts: len(concepts)).values
average_number_of_concepts = number_of_concepts_per_document.mean()
print('Prosečan broj koncepata-labela po dokumentu je: ', average_number_of_concepts)
Можемо издвојити и документ којем је придружен највећи број концепата-лабела.
document_index = number_of_concepts_per_document.argmax()
train_document_with_max_concepts = train_data_pd.iloc[document_index]
print('Naslov dokumenta sa najviše koncepata je: ', train_document_with_max_concepts['title'])
print('Broj koncepata pridruženih ovom dokumentu je: ', len(train_document_with_max_concepts['eurovoc_concepts']))
Ипак, нису сви концепти-лабеле равноправно присутни. Даље можемо издвојити концепте-лабеле и њихов број појављивања у скупу за обучавање. У томе нам може помоћи следећа функција.
import itertools
def concepts_frequency(data_pd):
# listа svih koncepata koji se pojavljuju u celom skupu је inicijalno prazna
all_concepts = []
# citamo red po red zadatog skupa podataka
# procitani red ce imati formu torke
for row in data_pd.itertuples():
# iz reda izdvajamo listu koncepata - lista koncepata se nalazi na poziciji 4
# njoj prethodi indeks reda, CELEX broj, naslov dokumenta i sadrzaj dokumenta
# listu koncepata dodajemo na kraj liste svih koncepata
all_concepts.append(row[4])
# kako lista svih koncepata predstavlja listu listi, ova naredba ce nam pomoci da dobijemo listu sa pojedinacnim konceptima
# na primer, ova naredba nam pomaze da od liste [[34, 21], [8, 9], [24]] dobijemo listu [34, 21, 8, 9, 24]
all_concepts_merged = list(itertools.chain(*all_concepts))
# izdvojene koncepte cemo smestiti u strukturu Series i pomocu njene funkcije value_counts brzo dobiti statistiku ponavljanja
all_concepts_statistics = pd.Series(all_concepts_merged).value_counts()
# generisanu statistiku cemo vratiti kao rezultat funkcije
return all_concepts_statistics
Позивом горње функције добијамо фреквенције концепата у скупу за обучавање.
train_data_concepts_frequency = concepts_frequency(train_data_pd)
Даље, издвојимо 10 најчешће коришћених концепата.
train_data_concepts_frequency.head(10)
Најчешће коришћени концепт има идентификатор 1309 и укупно 3, 645 појављивања. Њему одговара име import.
concept_names(eurovoc_pd, ['1309'])
Имена свих 10 најчешће коришћених концепата можемо добити позивом функције concept_names.
concept_names(eurovoc_pd, train_data_concepts_frequency.head(10).index)
Концепти који се појављују барем 50 пута у скупу за обучавање се могу добити следећим блоком кода.
train_data_concpets_frequency_50 = train_data_concepts_frequency[train_data_concepts_frequency >= 50]
Приметимо да ових концепата има значајно мање, свега 746.
train_data_concpets_frequency_50.shape
Задаци за вежбу:¶
- Занимљиво је да сви документи скупа података EurLex57k припадају истом сектору. Откријте о ком сектору је реч!
Помоћ: Информација о сектору којем документ припада одређена је почетним словом CELEX броја.
sectors = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 'C', 'E']
number_of_documents_per_sector = {
'0': 0,
'1': 0,
'2': 0,
'3': 0,
'4': 0,
'5': 0,
'6': 0,
'7': 0,
'8': 0,
'9': 0,
'C': 0,
'E': 0
}
for row in train_data_pd.itertuples():
sector = row[1][0]
number_of_documents_per_sector[sector] += 1
number_of_documents_per_sector
Сви документи припадају сектору број 3 тј. сектору правних актова (енгл. legal acts).
- Одредити колико докумената скупа за тренирање припада категорији транспорт. Документ припада категорији транспорт ако му је придружено неко од обележја 4806 (транспортне полисе), 4811 (организација транспорта), 4816 (друмски саобраћај), 4821 (морски и поморски саобраћај) или 4826 (аеро или свемирски транспорт).
transport_ids = ['4806', '4811', '4816', '4821', '4826']
documents = []
for row in train_data_pd.itertuples():
for id in transport_ids:
if id in row[4]:
documents.append(row[1])
print('Broj dokumenata koji pripada kategoriji transport je: ', len(documents))
print('CELEX brojevi trazenih dokumenata su: ', documents)
Провере ради, можемо издвојити наслов документа чији је CELEX broj 32009D0898 и њему придружене одреднице-лабеле.
transport_document_celex_id = '32009D0898'
transport_document_title = train_data_pd[train_data_pd['celex_id']==transport_document_celex_id]['title'].values[0]
transport_document_concepts = train_data_pd[train_data_pd['celex_id']==transport_document_celex_id]['eurovoc_concepts'].values[0]
print('Naslov dokumenta je: ', transport_document_title)
print('Pridruzeni EuroVoc koncepti su: ', transport_document_concepts)
- Приказати графиконом са стубићима однос директива, регулатива и одлука у скупу података EurLex57k. Подсетимо се да у сектору правних актова дескриптор означава тип документа. Латинично слово L означава директиве, латинично слово R означава регулативе, а латинично слово D одлуке.
import re
from matplotlib import pyplot as plt
directive_indexes = train_data_pd['celex_id'].apply(lambda id: re.match('^.[0-9]{4}L[0-9]{4}$', id) != None)
number_of_directives = train_data_pd[directive_indexes].shape[0]
regulation_indexes = train_data_pd['celex_id'].apply(lambda id: re.match('^.[0-9]{4}R[0-9]{4}$', id) != None)
number_of_regulations = train_data_pd[regulation_indexes].shape[0]
decision_indexes = train_data_pd['celex_id'].apply(lambda id: re.match('^.[0-9]{4}D[0-9]{4}$', id) != None)
number_of_decisions = train_data_pd[decision_indexes].shape[0]
plt.bar(['direktive', 'regulative', 'odluke'], [number_of_directives, number_of_regulations, number_of_decisions])
plt.title('Skup podataka EurLex57k')
plt.ylabel('Broj dokumenata u kategoriji')
plt.show()
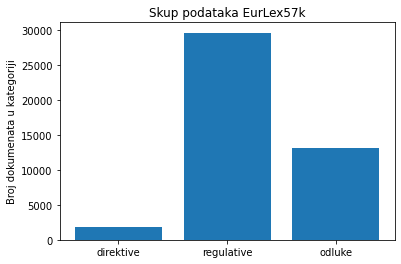
На основу приказа можемо закључити да су регулативе најбројнији тип докумената.