import warnings
warnings.filterwarnings('ignore')
Трансформери су мрежна архитектура новијег датума која се са великим успехом користи у многим задацима машинског учења. Посебно је познат трансформер са именом Берт (енгл. Bert) који је развио истраживачки тим компаније Гугл 2019. године. Берт за задати текстуални улаз може да генерише векторску репрезентацију погодну за разне задатке обраде природних језика као што су класификација текста, машинско превођења или генерисање текста. Постоје две варијанте трансформера Берт - мали модел има око 110 милиона параметара, а велики око 340 милиона. За обучавање Берт трансформера коришћена је велика колекција докумената на енглеском језику и импозантни рачунски ресурси. Занимљивости ради, велики Берт модел је трениран на 64 ТPU-a четири дана, а трошкови тренирања су процењени на 7, 000 долара. Зато по правилу користимо истрениране Берт моделе и профињујемо их и прилагођавамо (енгл. fine-tuning) другим задацима.
Заједница је пратећи пример трансформера Берт осмислила и многе друге трансформере као што су ДистилБерт, Роберта, Реформер, Биоберта итд. који надомешћују нека ограничења модела Берт, чине тренирање овог типа модела бржим или ефикаснијим или га прилагођавају неком специфичном домену као што је медицина или биоинформатика. Ми ћемо у раду користити модел који се зове LegalBert који је прилагођен правном домену.
Креирање LegarBert модела је представљено на конференцији EMNLP 2020. године у раду
Chalkidis Ilias et al. LEGAL-BERT: The Muppets straight out of Law School
Рад је доступан на овој адреси.
Библиотека transformers је специјална библиотека која омогућава удобан рад са трансформерима и задацима који прате припрему података, обучавање модела и анализу рада модела. Иза ове билиотеке стоји заједница која се зове HuggingFace .
Да бисмо демонстрирали капацитет модела LegalBert и његово разумевање текстова, маскираћемо неку реч правног текста и затражити од модела да погоди која реч се ту може наћи. Примера ради, можемо маскирати реч discrimination у реченици Any form of discrimination on a national, ethnic, racial and linguistic, religious and every other basis against national minorities and persons belonging to national minorities, shall be prohibited. која је преузета из Закона о заштити права и слобода националних мањина на енглеском језику.
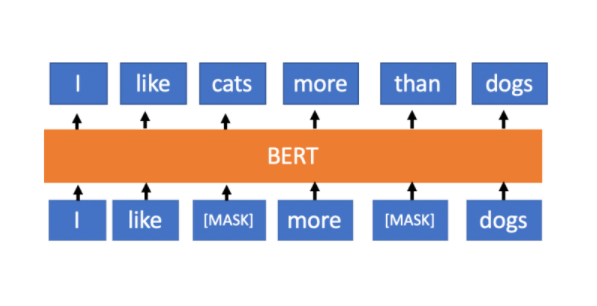
Прво ћемо из библиотеке transformers учитати функцију pipeline. Позивом ове функције креирају се именоване процедуре које обједињују све неопходне кораке од припреме текста до генерисања резултата.
from transformers import pipeline
Процедура која се бави погађањем недостајуће речи се зове fill-mask (на српском: попуни маску) па ћемо ову ниску проследити као први аргумент функцији pipeline. Како желимо да радимо са моделом LegalBert, други аргумент ће бити име овог модела у библиотеци transformers, а то је nlpaueb/legal-bert-base-uncased.
MODEL_PATH = 'nlpaueb/legal-bert-base-uncased'
mask_pipeline = pipeline('fill-mask', model=MODEL_PATH)
За маскирање речи у реченици искористићемо специјалан токен библиотеке unmasker.tokenizer.mask_token.
sentence = f'Any form of {mask_pipeline.tokenizer.mask_token} on a national, ethnic, racial and linguistic, religious and every other basis against national minorities and persons belonging to national minorities, shall be prohibited.'
Остаје још да позовемо процедуру и проверимо који су то речи могуће уместо маске.
mask_pipeline(sentence)
Можемо видети да је реч, вредност поља token_str, discirmination на првом месту и то са оценом која је јако висока (највећа оцена је 1).
Задаци за вежбу¶
- Одаберите произвољну реченицу из Закона о раду Републике Србије на енглеском језику који се може пронаћи на овој адреси, а затим проверите како ради модел LegalBert када се:
- маскира нека карактеристична реч правног домена попут provision, overtime или employee;
- маскира нека општа реч текста попут person, event или book;
- маскира број.