11. час: Учитавање табела из локалних датотека и из удаљених ресурса¶
На овом часу ћемо говорити о:
- учитавању података из табела које су припремљене у формату CSV;
- учитавање података из удаљених ресурса; и
- транспоновање табеле.
11.1. Учитавање података из локалних CSV датотека¶
Видели смо у претходним примерима да се најмукотрпнији посао обраде података састоји у томе да се подаци унесу у табелу. То је досадан посао који се често састоји у томе да се подаци просто прекуцају. Табеле са којима смо се сретали су зато биле веома мале. Модерна обрада података се, међутим, све више усмерава на анализу огромних количина података (енгл. big data) и ту прекуцавање података не долази у обзир.
Подаци се данас углавном прикупљају аутоматски, и програми за прикупљање података генеришу велике табеле података које после треба обрађивати. Постоје разни формати за табеларно представљање података, а најједноставнији од њих се зове CSV, (од енгл. comma separated values што значи "вредности раздвојене зарезима").
CSV датотека је текстуална датотека у којој редови одговарају редовима табеле, а подаци унутар истог реда су раздвојени зарезима. На пример, у фолдеру podaci се налази датотека StanovnistvoSrbije2017.csv која изгледа овако:
Старост,Мушко,Женско
0,33145,31444
1,33252,31105
2,33807,31475
3,34076,31952
4,33436,31643
5,34278,32505
6,33773,31523
7,33892,32185
8,34706,32396
9,34519,32177
10,34017,32064
11,34947,33251
... (итд) ...
84,11450,18529
85 и више,44817,78323
Ова табела садржи процену броја становника Републике Србије по годинама на дан 31.12.2017. Први ред табеле представља заглавље табеле које нам каже да табела има три колоне (Старост, Мушко, Женско). Врста
7,33892,32185
значи да се процењује да је 31.12.2017. у Србији било 33.892 седмогодишњих дечака и 32.185 седмогодишњих девојчица.
Библиотека pandas има функцију read_csv која учитава CSV датотеку и од ње прави табелу типа DataFrame. Ево примера:
import pandas as pd
stanovnistvo = pd.read_csv("podaci/StanovnistvoSrbije2017.csv")
Пошто је табела велика, приказаћемо само првих неколико редова. Функција head(N) приказује првих N редова табеле (енгл. head значи "глава"):
stanovnistvo.head(5)
Функција tail(N) приказује последњих N редова табеле (енгл. tail значи "реп"):
stanovnistvo.tail(5)
Табелу ћемо индексирати колоном "Старост":
stanovnistvo1 = stanovnistvo.set_index("Старост")
stanovnistvo1.head(5)
stanovnistvo1.tail(5)
11.2. Учитавање података из удаљених ресурса¶
Могуће је преузети и податке са удаљених ресурса без потребе да се они прво пребаце на локалну машину. Да бисмо приступили податку који се налази на некој другој машини потребно је да обе машине имају приступ Интернету и да знамо тачну локацију податка на удаљеној машини. Тачна локација било ког ресурса на Интернету је описана његовим URL-ом (од енгл. Universal Resource Locator, што значи "Универзални локатор ресурса").
На адреси
https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv
се налази јавно доступан списак свих држава на свету. Ову табелу можемо лако учитати наредбом read_csv:
drzave = pd.read_csv("https://raw.githubusercontent.com/cs109/2014_data/master/countries.csv")
drzave.head(10)
Помоћу наредбе read_html може се прочитати и табела директно из HTML кода неке веб странице. Рецимо, следећа наредба чита списак свих федералних јединица Сједињених Америчких Држава са одговарајуће странице Википедије:
US = pd.read_html("https://simple.wikipedia.org/wiki/List_of_U.S._states", header=0)[0]
Наредба read_html враћа релативно сложену структуру, али табела коју желимо да видимо је прва у тој структури. Зато иза наредбе следи конструкт [0] који враћа прву компоненту сложене структуре. Аргумент header=0 значи да прву врсту треба узети за заглавље табеле. Ево како изгледа табела:
US
11.3. Транспоновање табеле¶
Замена врста и колона табеле се зове транспоновање. Приликом транспоновања имена колона полазне табеле постају индекси нове табеле, док индексна колона полазне табеле одређује имена колона нове табеле:
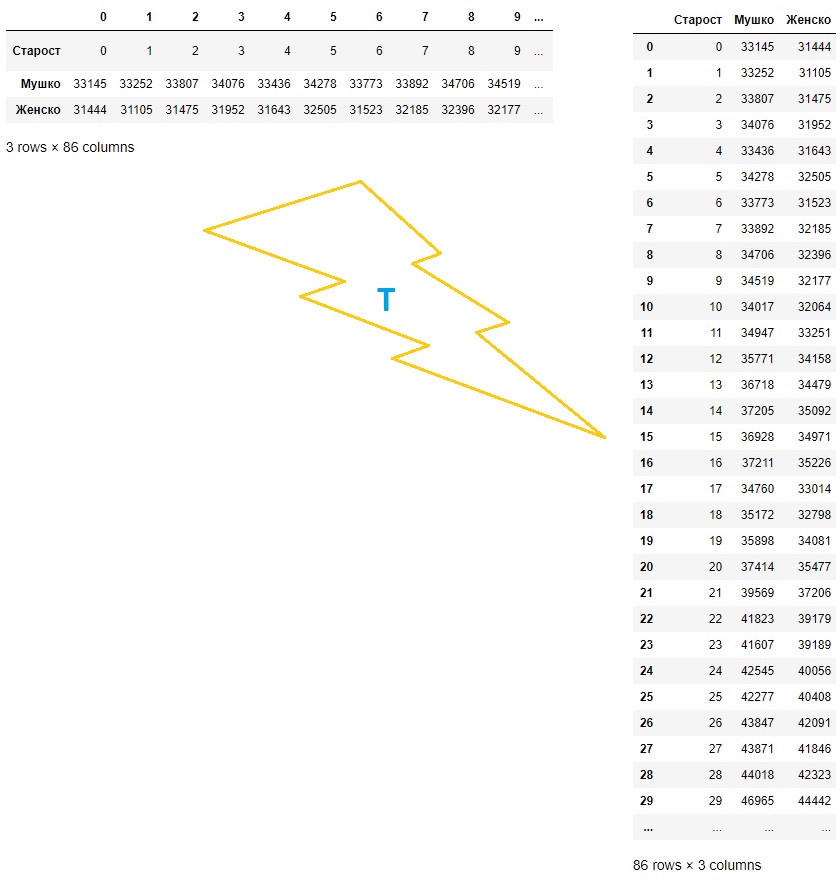
Транспоновање се често користи када табела има мало веома дугачких редова, па је у неким ситуацијама лакше посматрати транспоновану табелу која онда има пуно релативно кратких редова. Функције head и tail нам тада омогућују да се брзо упознамо са почетком и крајем табеле и да стекнемо неку интуицију о томе како табела изгледа.
Важно је рећи и то да се са табелама може радити и без транспоновања, јер све што можемо да урадимо на колонама табеле можемо да урадимо и на врстама. И поред тога, транспоновање се често користи јер је библиотека pandas оптимизована за рад по колонама табеле.
Табела се транспонује тако што се на њу примени функција Т која као резултат враћа нову, транспоновану табелу.
Ево примера са оценама:
razred = [["Ана", 5, 3, 5, 2, 4, 5],
["Бојан", 5, 5, 5, 5, 5, 5],
["Влада", 4, 5, 3, 4, 5, 4],
["Гордана", 5, 5, 5, 5, 5, 5],
["Дејан", 3, 4, 2, 3, 3, 4],
["Ђорђе", 4, 5, 3, 4, 5, 4],
["Елена", 3, 3, 3, 4, 2, 3],
["Жаклина", 5, 5, 4, 5, 4, 5],
["Зоран", 4, 5, 4, 4, 3, 5],
["Ивана", 2, 2, 2, 2, 2, 5],
["Јасна", 3, 4, 5, 4, 5, 5]]
ocene = pd.DataFrame(razred)
ocene.columns=["Име", "Српски", "Енглески", "Математика", "Физика", "Хемија", "Ликовно"]
ocene1 = ocene.set_index("Име")
ocene1
Транспоновану табелу добијамо овако:
ocene2 = ocene1.T
ocene2
Хајде још да се уверимо да су врсте и колоне замениле места и у пољима index и columns. У полазној табели је:
ocene1.index
ocene1.columns
А у транспонованој табели је:
ocene2.index
ocene2.columns
Како смо раније већ видели, просек оцена по предметима добијамо лако:
for predmet in ocene1.columns:
print(predmet, "->", ocene1[predmet].mean())
Да бисмо добили просек оцена по ученицима, можемо да приступимо врстама табеле користећи функцију loc како смо то већ видели, али можемо и да употребимо транспоновану табелу (рачунање просека по колонама, јер су колоне транспоноване табеле заправо врсте полазне табеле):
for ucenik in ocene2.columns:
print(ucenik, "->", ocene2[ucenik].mean())
Ево још једног примера. У фолдеру podaci се налази датотека TemperaturneAnomalije.csv која садржи податке о томе за колико степени Целзијуса је средња измерена температура на Земљи већа од оптималне у последњих 40 година. Ова табела има два дугачка реда који изгледају овако:
1977,1978,1979,1980,1981,...
0.22,0.14,0.15,0.3,0.37,...
У првом реду се налазе године (1977-2017), а у другом измерена температурна аномалија. Видимо да табела нема заглавље. Зато ћемо је учитати на следећи начин:
temp_anomalije = pd.read_csv("podaci/TemperaturneAnomalije.csv", header = None)
temp_anomalije
Дакле, ако табела са подацима нема заглавље, приликом учитавања се то мора нагласити функцији read_csv тако што се наведе header = None.
Да бисмо добили податке у облику који се лакше обрађује, транспоноваћемо табелу и онда ћемо колонама транспоноване табеле дати одговарајућа имена.
temp_anomalije1 = temp_anomalije.T
temp_anomalije1.columns = ["Година", "Аномалија"]
Ево првих неколико редова табеле:
temp_anomalije1.head(10)
Табелу ћемо индексирати колоном "Година":
temp_anomalije2 = temp_anomalije1.set_index("Година")
temp_anomalije2.head(5)
Приказаћемо температурне аномалије дијаграмом:
import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
plt.plot(temp_anomalije2.index, temp_anomalije2["Аномалија"], color="r")
plt.title("Температурне аномалије у периоду 1977--2017")
plt.show()
plt.close()

11.4. Задаци¶
Задатке реши у Џупајтеру.
Задатак 1. У фолдеру podaci се налази датотека StanovnistvoSrbije2017.csv (која има заглавље). Табела има три колоне које се зову "Старост", "Мушко" и "Женско".
(а) Учитај датотеку у структуру података DataFrame и индексирај табелу колоном "Старост".
(б) Прикажи процењени број мушкараца и жена по старости линијским дијаграмом.
Задатак 2. Ученици једног разреда су скакали у даљ. Сваки ученик је скакао три пута и резултати су дати у датотеци SkokUDalj.csv која се налази у фолдеру podaci. Табела има заглавље и састоји се од четири колоне: "Презиме и име", "Скок1", "Скок2" и "Скок3".
(а) Учитај датотеку у структуру података DataFrame.
(б) Прикажи ове податке линијским дијаграмом који ће имати три линије, једна линија за сваки скок. Дијаграм треба да има легенду.
Задатак 3. На адреси
https://raw.githubusercontent.com/resbaz/r-novice-gapminder-files/master/data/gapminder-FiveYearData.csv
се налази јавно доступна табела са списком држава света и неким параметрима економског развоја тих држава праћеним у интервалима од 5 година.
Табела има следеће колоне:
- country = држава
- year = година на коју се односе подаци
- pop = број становника (енгл. population)
- continent = континент
- lifeExp = очекивани животни век у годинама (енгл. life expextancy)
- gdpPercap = БДП по глави становника у америчким доларима (енгл. GDP per capitem)
Учитај ову табелу у структуру података DataFrame и прикажи првих 20 редова табеле, као и последњих 10 редова табеле.