У овој секцији упознаћемо детаљније тезаурус EuroVoc и начин на који је организован.
Тезаурус EuroVoc је врста речника која обједињује концепте који се придружују званичним документима Европске уније зарад систематичне организације. На пример, документу који се бави миграцијама се могу придружити концепти family migration или geographical mobility. Овако контролисани вокабулар омогућава униформу организацију докумената између свих чланица Европске уније и њихово лакше претраживање.
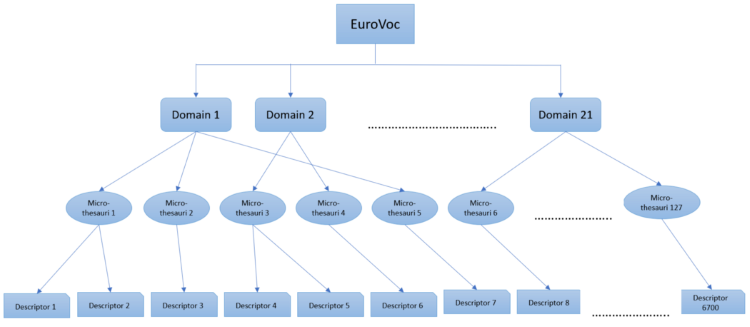
Информације које су садржане у тезаурусу су физички подељене у већи број датотека и могу се преузети са званичне адресе у већем броју формата. Ми ћемо користити архиву eurovoc_xml.zip која садржи датотеке у формату XML, као и попис свих концепата DOC_1.xml.
Посебно, на нивоу архиве пратићемо документе који се односе на енглески језик тј. документе који у називу имају суфикс _eng.
За обраду информација записаних у XML формату користићемо библиотеку BeаutifulSoup. Функције ове библиотеке нам омогућавају да се лако крећемо кроз хијерархијску структуру докумената, као и да једноставно издвојимо елементе на основу имена или атрибута који им је придружен.
from bs4 import BeautifulSoup
Домени¶
На највишем нивоу хијерархије тезауруса налазе се домени. Домени се представљају двоцифреним идентификаторима и има их укупно 21. Физички, информације о доменима тезауруса се налазе у датотеци dom_en.xml. Следећим блоком кода се из ове датотека могу издвојити идентификатори и имена домена.
domains_file = open('data/eurovoc_thesaurus/dom_en.xml', 'r')
domains_file_content = domains_file.read()
domains_soup = BeautifulSoup(domains_file_content, 'html.parser')
domain_ids = [id.get_text() for id in domains_soup.find_all('domaine_id')]
domain_names = [name.get_text() for name in domains_soup.find_all('libelle')]
print('Identifikatori i imena domena: ')
for id, name in zip (domain_ids, domain_names):
print (id, name)
Сличан блок кода искористићемо да сачувамо овај пар идентификатора и имена у датотеци domains_with_id_and_name.txt.
domains_with_id_and_name = {}
for id, name in zip (domain_ids, domain_names):
domains_with_id_and_name[id] = name
with open('data/domains_with_id_and_name.txt', 'w') as file:
file.write(str(domains_with_id_and_name))
Микротезауруси¶
Микротезауруси представљају сегменте тезауруса који се односе на специфичне домене. Њих карактеришу четвороцифрени идентификатори чије се прве две цифре преклапају са идентификатором домена. Тако, на пример, домену "наука" са идентификатором 36 одговарају два микротезауруса 3606 и 3611 - први обједињује концепте који се односе на природне и примењене науке, а други концепте који се односе на хуманистичке науке. Микротезауруса има укупно 127, а њихова имена и кодови се могу прочитати из датотеке са именом thes_en.xml.
Следећим блоком кода ћемо издвојити имена и кодове микротезауруса.
microthesaurus_file = open('data/eurovoc_thesaurus/thes_en.xml', 'r')
microthesaurus_file_content = microthesaurus_file.read()
microthesaurus_soup = BeautifulSoup(microthesaurus_file_content, 'html.parser')
microthesaurus_ids = [id.get_text() for id in microthesaurus_soup.find_all('thesaurus_id')]
microthesaurus_names = [name.get_text() for name in microthesaurus_soup.find_all('libelle')]
Identifikatori i imena mikrotezaurusa:
zip(microthesaurus_ids, microthesaurus_names)
На основу прочитаних информација можемо објединити домене и микротезаурусе који им припадају. Искористићемо својство да се прве две цифре идентификатора микротезауруса преклапају са идентификатором домена.
microthesauruses_per_domain = {}
for domain_id in domain_ids:
microthesauruses_per_domain[domain_id] = []
for microthesaurus_id in microthesaurus_ids:
domain_id = microthesaurus_id[0:2]
microthesauruses_per_domain[domain_id].append(microthesaurus_id)
microthesauruses_per_domain
Највећи број микротезауруса је придружен домену "финансије" са идентификатором 24.
for (domain, all_thesauruses) in microthesauruses_per_domain.items():
print ('Domen ', domain, ': broj mikrotezaurusa: ', len(all_thesauruses))
Концепти и њихове релације¶
Концепти тезауруса су, такође, хијерархијски организовани. Главни концепти (енгл. top terms) се налазе на врху хијерархије и везани су за сам микротезаурус, док су преостали концепти везани за главне концепте према нивоима специфичности. Актуелна верзија тезауруса подржава везе генеричког (на пример, концепти protected area и national park) и партитивног (на пример, chemistry и analytical chemistry) типа, као и угњежђавања највише дубине два.
Издвајање свих концепата микротезауруса¶
Сви концепти тезауруса се могу прочитати из датотеке DOC_1.xml. Нама ће бити занимљиво да издвојимо концепте који припадају одређеном микротезаурусу - идентификатори концепата ће нам значити за само кодирање док ће нам имена ових концепата омогућити да лакше испратимо организацију.
Следећим блоком кода ћемо припремити датотеку DOC_1.xml за рад, док ће нам функција get_concepts_for_microthesaurus омогућити да из овако припремљене датотеке за задати идентификатор микротезауруса прочитамо концепте који му припадају.
main_thesaurus_file = open('data/eurovoc_thesaurus/DOC_1.xml', 'r', encoding='utf-8')
main_thesaurus_content = main_thesaurus_file.read()
main_thesaurus_soup = BeautifulSoup(main_thesaurus_content, 'html.parser')
def get_concepts_for_microthesaurus(microthesaurus_id, main_thesaurus_soup):
concepts = {}
for record in main_thesaurus_soup.find_all(thesaurus_id=microthesaurus_id):
id = record['id']
concept_wrapper = record.parent.parent.find_all('xs:documentation')[0].get_text()
concept = concept_wrapper[0:concept_wrapper.find('/')-1]
concepts[id] = concept
return concepts
У наставку можемо видети све концепте микротезауруса за природне и примењене науке.
get_concepts_for_microthesaurus('3606', main_thesaurus_soup)
Сдржај датотеке DOC_1.xml можемо искористи и за очитавање имена појединачних концепата на основу њихових идентификатора. Функција get_concept_name имплементира баш овај задатак. Њеним коришћењем је генерисан и листинг свих концепата eurovoc_concepts.jsonl који смо упознали у секцији o EuroLex57k скупу података.
def get_concept_name(concept_id, main_thesaurus_soup):
concept_value = "eurovoc:" + concept_id
concept_parent = main_thesaurus_soup.find("xs:enumeration", value=concept_value)
concept_wrapper = concept_parent.find('xs:documentation').get_text()
concept = concept_wrapper[0:concept_wrapper.find('/')-1]
return concept
get_concept_name('1016', main_thesaurus_soup)
Издвајање главних концепата микротезауруса¶
Главни концепти тезауруса EuroVoc су концепти који се налазе на врху хијерархије микротезауруса и који немају даљих уопштења. Док је све концепте микротезауруса лако издвојити, да би се добили ови концепти потребно је нешто мало више техничког посла. Датотека mappings.xml која садржи информације о овим мапирањима главних концепата и микротезауруса преузета је са ове адресе.
top_terms_file = open('data/eurovoc_thesaurus/mappings.xml', 'r')
top_terms_file_content = top_terms_file.read()
top_terms_soup = BeautifulSoup(top_terms_file_content, 'html.parser')
Из овако припремљеног документа могу се издвојити линкови до страница које садрже попис главних концепата одговарајућих микротезауруса. Линкова има укупно 127 - са сваки микротезаурус по један. Функција get_top_terms нам омогућава да пратећи линк дохватимо тражене информације.
import requests
top_terms_resources = [resource['rdf:resource'] for resource in top_terms_soup.find_all('ns5:haspart')]
def get_top_terms(resource_link):
response = requests.get(resource_link)
if response.status_code != 200:
print('Resource ', resource_link, 'could not be fetched (status code: ', response.status_code, ')')
return
response_text = response.text
soup = BeautifulSoup(response_text, 'html.parser')
microthesaurus_id = soup.find('skos:notation').text
top_terms = []
for top_term in soup.find_all('skos:hastopconcept'):
resource = top_term['rdf:resource']
index = resource.rfind('/') + 1
id = resource[index: ]
top_terms.append(id)
return microthesaurus_id, top_terms
top_terms_per_microthesaurus = {}
for top_term_resource in top_terms_resources:
microthesaurus_id, top_terms = get_top_terms(top_term_resource)
top_terms_per_microthesaurus[microthesaurus_id] = top_terms
top_terms_per_microthesaurus
Издвајање концепата на основу хијерархије¶
Хијерархијске релације између концепата су пописане у датотеци relation_bt.xml.
relations_file = open('data/eurovoc_thesaurus/relation_bt.xml', 'r')
relations_content = relations_file.read()
relations_soup = BeautifulSoup(relations_content, 'html.parser')
Функција get_children_for_concept нам може помоћи да прочитамо идентификаторе концепата који се налазе у хијерархији испод задатог концепта (обично такве концепте зовемо децом).
def get_children_for_concept(concept_id, relations_soup):
records = relations_soup.find_all('record')
source_ids = []
for record in records:
source_id = record.select('source_id')[0].get_text()
cible_id = record.select('cible_id')[0].get_text()
if cible_id == concept_id:
source_ids.append(source_id)
return source_ids
Можемо проверити који се то концепти налазе у хијерархији испод концепта population dynamics са идентификатором 3318.
get_children_for_concept('3318', relations_soup)
Имена ових концепата можемо добити помоћу функције get_concept_name.
children_concepts_3318 = get_children_for_concept('3318', relations_soup)
for concept in children_concepts_3318:
concept_name = get_concept_name(concept, main_thesaurus_soup)
print(concept_name)
Како ЕuroVoc хијерархија дозвољава угњежђавање концепата до дубине два, уколико желимо да добијемо и ову децу за задати концепт можемо искористити функцију get_all_children_for_concept.
def get_all_children_for_concept(concept_id, relations_soup):
all_children = []
children = get_children_for_concept(concept_id, relations_soup)
for child in children:
all_children.append(child)
children_level_1 = get_children_for_concept(child, relations_soup)
for inner_child in children_level_1:
all_children.append(inner_child)
children_level_2 = get_children_for_concept(inner_child, relations_soup)
for very_inner_child in children_level_2:
all_children.append(very_inner_child)
return all_children
Тако се, на пример, сва деца концепта "демографија" са идентификатором 385 могу добити следећим позивом:
all_children_concepts_385 = get_all_children_for_concept('385', relations_soup)
for concept in all_children_concepts_385:
concept_name = get_concept_name(concept, main_thesaurus_soup)
print(concept_name)
Упаривање домена и свих концепата који му припадају¶
Следећим блоком кода упарићемо информације о доменима и концептима који им припадају. Оваква структура нам је неопходна за трансформацију обележја скупа EurlLex57k на начин који је подесан за вишелабеларну класификацију.
concepts_per_domain = {}
for (domain, microthesauruses) in microthesauruses_per_domain.items():
concepts = []
for microthesaurus_id in microthesauruses:
concepts_per_microthesaurus = get_concepts_for_microthesaurus(microthesaurus_id, main_thesaurus_soup)
concepts += concepts_per_microthesaurus
concepts_per_domain[domain] = concepts
Сада се лако могу добити сви концепти који припадају домену науке. Има их укупно 133!
science_concepts = concepts_per_domain['36']
len(science_concepts)
Овако креирану структуру ћемо сачувати за даље коришћење у датотеци са именом concepts_per_domain.txt.
with open('data/concepts_per_domain.txt', 'w') as file:
file.write(str(concepts_per_domain))