7. Indeksiranje i transponovanje tabele¶
U ovoj lekciji ćemo govoriti o:
- indeksiranju tabele radi fleksibilnijeg pristupa elementima tabele;
- pristupu vrstama i pojedinačnim lokacijama indeksirane tabele;
- računanju sa celim redovima i kolonama tabele; i
- transponovanju tabele.
7.1. Indeksiranje¶
Videli smo da je rad sa kolonama tabele veoma jednostavan.
Da bismo mogli da radimo sa redovima tabele treba prvo da nađemo jednu kolonu čija vrednost jednoznačno određuje ceo red tabele. Na primer, u tabeli sa sa prošlog časa
| Ime | Pol | Starost | Masa | Visina |
|---|---|---|---|---|
| Ana | ž | 13 | 46 | 160 |
| Bojan | m | 14 | 52 | 165 |
| Vlada | m | 13 | 47 | 157 |
| Gordana | ž | 15 | 54 | 165 |
| Dejan | m | 15 | 56 | 163 |
| Đorđe | m | 13 | 45 | 159 |
| Elena | ž | 14 | 49 | 161 |
| Žaklina | ž | 15 | 52 | 164 |
| Zoran | m | 15 | 57 | 167 |
| Ivana | ž | 13 | 45 | 158 |
| Jasna | ž | 14 | 51 | 162 |
kolona "Ime" je takva kolona (kolona "Visina" nije pogodna jer imamo dvoje dece sa visinom 165, pa kada kažemo "dete sa visinom 165" nije jasno o kome se radi; isto tako ni kolone "Pol", "Starost" i "Masa" nisu pogodne).
Takva kolona se zove ključ jer je ona ključna za pristupanje redovima tabele. Ako želimo da pristupamo elementima tabele po redovima, moramo sistemu da prijavimo koju kolonu ćemo koristiti kao ključ. To se postiže pozivom funkcije set_index kojoj prosledimo ime kolone, a ona vrati novu tabelu "indeksiranu po datom ključu":
import pandas as pd
podaci = [["Ana", "ž", 13, 46, 160],
["Bojan", "m", 14, 52, 165],
["Vlada", "m", 13, 47, 157],
["Gordana", "ž", 15, 54, 165],
["Dejan", "m", 15, 56, 163],
["Đorđe", "m", 13, 45, 159],
["Elena", "ž", 14, 49, 161],
["Žaklina", "ž", 15, 52, 164],
["Zoran", "m", 15, 57, 167],
["Ivana", "ž", 13, 45, 158],
["Jasna", "ž", 14, 51, 162]]
tabela = pd.DataFrame(podaci)
tabela.columns=["Ime", "Pol", "Starost", "Masa", "Visina"]
tabela1=tabela.set_index("Ime")
Nova tabela (tabela1) se od stare (tabela) razlikuje samo po tome što redovi više nisu indeksirani brojevima (0, 1, 2, ...) već imenima dece (Ana, Bojan, Vlada, ...). Evo stare (neindeksirane tabele) koja ima kolonu "Ime" i čiji redovi su indeksirani brojevima:
tabela
A evo i nove tabele u kojoj su redovi indeksirani imenima dece:
tabela1
Kolona "Ime" je i dalje prisutna u tabeli tabela1, ali ima poseban status. Ako pokušamo da joj pristupimo kao "običnoj" koloni dobićemo grešku:
tabela1["Ime"]
Međutim, ona je tu kao indeksna kolona:
tabela1.index
Ako želimo da prikažemo visinu dece u grupi grafikonom tako da imena dece budu na horizontalnoj osi, to sada možemo uraditi ovako:
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
plt.bar(tabela1.index, tabela1["Visina"])
plt.title("Visina dece u grupi")
plt.show()
plt.close()
Oznake na horizontalnoj osi uzimamo iz indeksne kolone tabela1.index, dok podatke o visini stubića uzimamo iz kolone tabela1["Visina"].
7.2. Pristup vrstama i pojedinačnim ćelijama indeksirane tabele¶
Struktura podataka DataFrame je optimizovana za rad sa kolonama tabele. Srećom, kada imamo indeksiranu tabelu kao što je to tabela1, koristeći funkciju loc (od engl. location što znači "lokacija, položaj, mesto") možemo da pristupamo redovima tabele, kao i pojedinačnim ćelijama tabele.
Podatke o pojedinačnim redovima tabele možemo da vidimo ovako:
tabela1.loc["Dejan"]
Kao argument funkcije loc možemo da navedemo i raspon, i tako ćemo dobiti odgovarajući deo tabele:
tabela1.loc["Dejan":"Zoran"]
Ako kao drugi argument funkcije loc navedemo ime kolone, recimo ovako:
tabela1.loc["Dejan", "Visina"]
dobićemo informaciju o Dejanovoj visini.
tabela1.loc["Dejan", "Visina"]
Evo kako možemo da dobijemo informaciju o masi i visini nekoliko dece:
tabela1.loc["Dejan":"Zoran", "Masa":"Visina"]
7.3. Račun po vrstama i kolonama tabele¶
Krenimo od jednog primera. U ćeliji ispod date su ocene nekih učenika iz informatike, engleskog, matematike, fizike, hemije i likovnog:
razred = [["Ana", 5, 3, 5, 2, 4, 5],
["Bojan", 5, 5, 5, 5, 5, 5],
["Vlada", 4, 5, 3, 4, 5, 4],
["Gordana", 5, 5, 5, 5, 5, 5],
["Dejan", 3, 4, 2, 3, 3, 4],
["Đorđe", 4, 5, 3, 4, 5, 4],
["Elena", 3, 3, 3, 4, 2, 3],
["Žaklina", 5, 5, 4, 5, 4, 5],
["Zoran", 4, 5, 4, 4, 3, 5],
["Ivana", 2, 2, 2, 2, 2, 5],
["Jasna", 3, 4, 5, 4, 5, 5]]
Sada ćemo od ovih podataka napraviti tabelu čije kolone će se zvati "Ime", "Informatika", "Engleski", "Matematika", "Fizika", "Hemija", "Likovno" i koja će biti indeksirana po koloni "Ime":
ocene = pd.DataFrame(razred)
ocene.columns=["Ime", "Informatika", "Engleski", "Matematika", "Fizika", "Hemija", "Likovno"]
ocene1 = ocene.set_index("Ime")
ocene1
Ako želimo da izračunamo prosek po predmetima, treba na svaku kolonu ove tabele da primenimo funkciju mean. Lista sa imenima svih kolona tabele ocene1 se dobija kao ocene1.columns, pa sada samo treba da prođemo kroz ovu listu i za svaku kolonu da izračunamo prosek:
for predmet in ocene1.columns:
print(predmet, "->", round(ocene1[predmet].mean(), 2))
Da bismo izračunali prosečne ocene svakog učenika funkciju mean ćemo primeniti na vrste tabele koje dobijamo pozivom funkcije loc. Pogledajmo, prvo, kako to možemo da uradimo za jednog učenika:
print("Đorđe ima sledeće ocene:")
print(ocene1.loc["Đorđe"])
print("Prosek njegovih ocena je:", round(ocene1.loc["Đorđe"].mean(), 2))
Spisak svih učenika se nalazi u indeksnoj koloni, pa proseke po svim učenicima možemo da izračunamo ovako:
for ucenik in ocene1.index:
print(ucenik, "->", round(ocene1.loc[ucenik].mean(), 2))
7.4. Transponovanje tabele¶
Zamena vrsta i kolona tabele se zove transponovanje. Prilikom transponovanja imena kolona polazne tabele postaju indeksi nove tabele, dok indeksna kolona polazne tabele određuje imena kolona nove tabele:
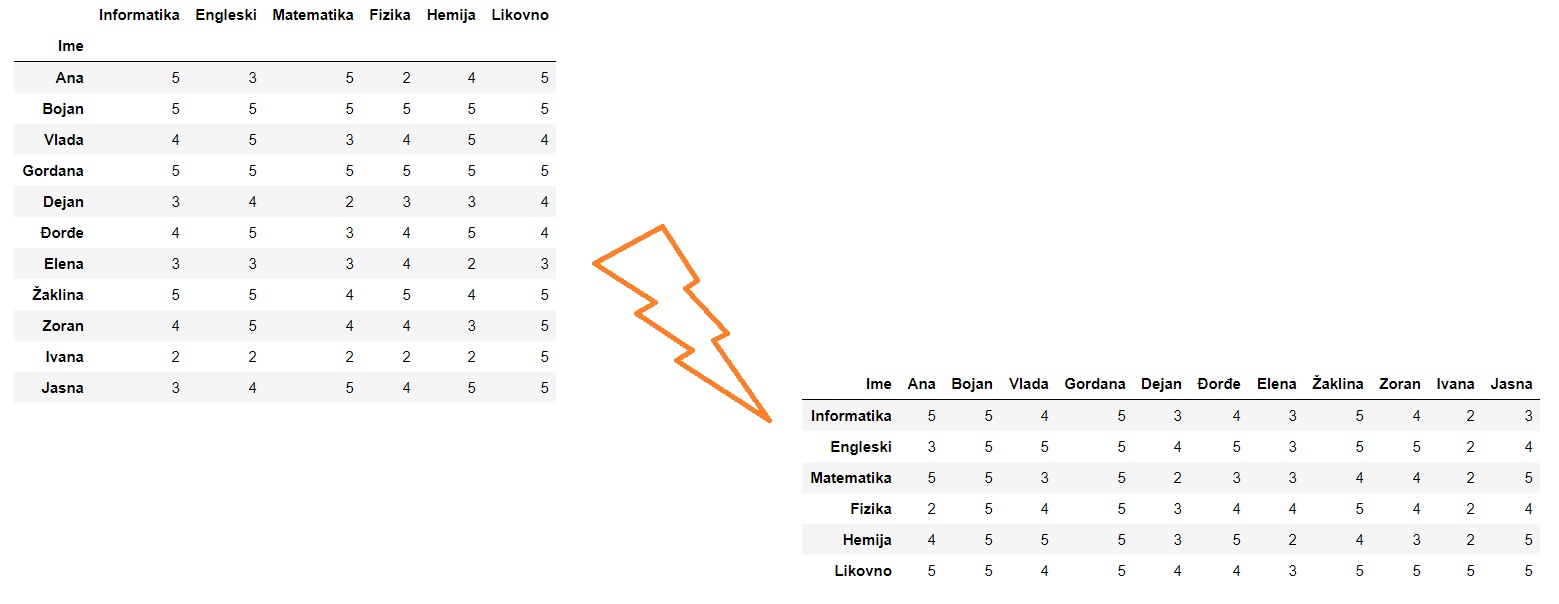
Transponovanje se često koristi kada tabela ima malo veoma dugačkih redova, pa je u nekim situacijama lakše posmatrati transponovanu tabelu koja onda ima puno relativno kratkih redova. Funkcije head i tail nam tada omogućuju da se brzo upoznamo sa početkom i krajem tabele i da steknemo neku intuiciju o tome kako tabela izgleda.
Važno je reći i to da se sa tabelama može raditi i bez transponovanja, jer sve što možemo da uradimo na kolonama tabele možemo da uradimo i na vrstama. I pored toga, transponovanje se često koristi jer je biblioteka pandas optimizovana za rad po kolonama tabele.
Tabela se transponuje tako što se na nju primeni funkcija T koja kao rezultat vraća novu, transponovanu tabelu.
Evo primera sa ocenama:
ocene1
Transponovanu tabelu dobijamo ovako:
ocene2 = ocene1.T
ocene2
Hajde još da se uverimo da su vrste i kolone zamenile mesta i u poljima index i columns. U polaznoj tabeli je:
ocene1.index
ocene1.columns
A u transponovanoj tabeli je:
ocene2.index
ocene2.columns
Kako smo ranije već videli, prosek ocena po predmetima dobijamo lako:
for predmet in ocene1.columns:
print(predmet, "->", round(ocene1[predmet].mean(), 2))
Da bismo dobili prosek ocena po učenicima, možemo da pristupimo vrstama tabele koristeći funkciju loc kako smo to već videli, ali možemo i da upotrebimo transponovanu tabelu (računanje proseka po kolonama, jer su kolone transponovane tabele zapravo vrste polazne tabele):
for ucenik in ocene2.columns:
print(ucenik, "->", round(ocene2[ucenik].mean(), 2))
7.5. Zadaci¶
Zadatke reši u Džupajteru.
Zadatak 1. Pažljivo pogledaj ovaj Pajton program pa odgovori na pitanja koja slede:
import pandas as pd
podaci = [["Ana", "ž", 13, 46, 160],
["Bojan", "m", 14, 52, 165],
["Vlada", "m", 13, 47, 157],
["Gordana", "ž", 15, 54, 165],
["Dejan", "m", 15, 56, 163],
["Đorđe", "m", 13, 45, 159],
["Elena", "ž", 14, 49, 161],
["Žaklina", "ž", 15, 52, 164],
["Zoran", "m", 15, 57, 167],
["Ivana", "ž", 13, 45, 158],
["Jasna", "ž", 14, 51, 162]]
tabela = pd.DataFrame(podaci)
tabela.columns=["Ime", "Pol", "Starost", "Masa", "Visina"]
tabela1=tabela.set_index("Ime")
temp_anomalije = pd.read_csv("podaci/TemperaturneAnomalije.csv", header=None)
temp_anomalije1 = temp_anomalije.T
temp_anomalije1.columns = ["Godina", "Anomalija"]
- U čemu je razlika između tabela
tabelaitabela1? - Šta predstavlja izraz
tabela1.index? - Šta je vrednost izraza
tabela1.loc["Đorđe"]? - Šta je vrednost izraza
tabela1.loc["Đorđe", "Visina"]? - Šta je vrednost izraza
tabela.loc["Đorđe", "Visina"]? - Zašto smo na tabelu
temp_anomalijeprimenili funkcijuT? - Koliko kolona ima tabela
temp_anomalije1?
Zadatak 2. Evo troškova života jedne porodice tokom jedne godine, po mesecima (svi iznosi su predstavljeni u dinarima):
| Stavka | Jan | Feb | Mar | Apr | Maj | Jun | Jul | Avg | Sep | Okt | Nov | Dec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Stanarina | 8.251 | 8.436 | 8.524 | 8.388 | 8.241 | 8.196 | 8.004 | 7.996 | 7.991 | 8.015 | 8.353 | 8.456 |
| Struja | 4.321 | 4.530 | 4.115 | 3.990 | 3.985 | 3.726 | 3.351 | 3.289 | 3.295 | 3.485 | 3.826 | 3.834 |
| Telefon (fiksni) | 1.425 | 1.538 | 1.623 | 1.489 | 1.521 | 1.485 | 1.491 | 1.399 | 1.467 | 1.531 | 1.410 | 1.385 |
| Telefon (mobilni) | 2.181 | 2.235 | 2.073 | 1.951 | 1.989 | 1.945 | 3.017 | 2.638 | 2.171 | 1.831 | 1.926 | 1.833 |
| TV i internet | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 |
| Prevoz | 1.830 | 1.830 | 1.830 | 1.830 | 1.950 | 1.950 | 1.450 | 1.450 | 1.950 | 1.950 | 2.050 | 2.050 |
| Hrana | 23.250 | 23.780 | 24.019 | 24.117 | 24.389 | 24.571 | 24.736 | 24.951 | 25.111 | 25.389 | 25.531 | 25.923 |
| Ostalo | 4.500 | 3.700 | 5.100 | 3.500 | 2.750 | 4.250 | 7.320 | 8.250 | 3.270 | 4.290 | 3.200 | 8.390 |
U ćeliji ispod su isti podaci predstavljeni listom:
troskovi = [
["Stanarina", 8251, 8436, 8524, 8388, 8241, 8196, 8004, 7996, 7991, 8015, 8353, 8456],
["Struja", 4321, 4530, 4115, 3990, 3985, 3726, 3351, 3289, 3295, 3485, 3826, 3834],
["Telefon (fiksni)", 1425, 1538, 1623, 1489, 1521, 1485, 1491, 1399, 1467, 1531, 1410, 1385],
["Telefon (mobilni)", 2181, 2235, 2073, 1951, 1989, 1945, 3017, 2638, 2171, 1831, 1926, 1833],
["TV i internet", 2399, 2399, 2399, 2399, 2399, 2399, 2399, 2399, 2399, 2399, 2399, 2399 ],
["Prevoz", 1830, 1830, 1830, 1830, 1950, 1950, 1450, 1450, 1950, 1950, 2050, 2050],
["Hrana", 23250, 23780, 24019, 24117, 24389, 24571, 24736, 24951, 25111, 25389, 25531, 25923],
["Ostalo", 4500, 3700, 5100, 3500, 2750, 4250, 7320, 8250, 3270, 4290, 3200, 8390]
]
(a) Predstavi tabelu strukturom DataFrame. Indeksiraj tabelu.
(b) Izračunaj i ispiši prosečnu potrošnju ove porodice po stavkama (koliko je porodica prosečno potrošila na stanarinu, koliko na struju, itd).
Zadatak 3. Učenici osmog razreda jedne škole su anketirani o tome koju vrstu filmova najradije gledaju. Podaci ankete su dati u sledećoj tabeli (u koju nisu uneti nevažeći i besmisleni odgovori):
| Žanr | 8-1 | 8-2 | 8-3 | 8-4 | 8-5 |
|---|---|---|---|---|---|
| Komedija | 4 | 3 | 5 | 2 | 3 |
| Horor | 1 | 0 | 2 | 1 | 6 |
| Naučna fantastika | 10 | 7 | 9 | 8 | 9 |
| Avanture | 4 | 3 | 4 | 2 | 2 |
| Istorijski | 1 | 0 | 2 | 0 | 0 |
| Romantični | 11 | 10 | 7 | 9 | 8 |
(a) Formiraj odgovarajuću tabelu pozivom funkcije DataFrame. Indeksiraj tabelu kolonom "Žanr".
(b) Izračunaj i ispiši koliko glasova je dobio svaki od navedenih žanrova.
(v) Za svako odeljenje izračunaj i ispiši koliko je bilo validnih glasova.
(g) Koliko je ukupno učenika osmih razreda učestvovalo u anketiranju? (Računamo samo učenike koji su dali validne odgovore na anketu.)
Zadatak 4. Nutritivni podaci za neke namirnice su dati u sledećoj tabeli:
| Namirnica (100g) | Energetska vrednost (kcal) | Ugljeni hidrati (g) | Belančevine (g) | Masti (g) |
|---|---|---|---|---|
| Crni hleb | 250 | 48,2 | 8,4 | 1,0 |
| Beli hleb | 280 | 57,5 | 6,8 | 0,5 |
| Kisela pavlaka (10% m.m.) | 127 | 4,0 | 3,1 | 10,5 |
| Margarin | 532 | 4,6 | 3,2 | 1,5 |
| Jogurt | 48 | 4,7 | 4,0 | 3,3 |
| Mleko (2,8% m.m.) | 57 | 4,7 | 3,3 | 2,8 |
| Salama parizer | 523 | 1,0 | 17,0 | 47,0 |
| Pršuta | 268 | 0,0 | 25,5 | 18,4 |
| Pileća prsa | 110 | 0,0 | 23,1 | 1,2 |
U ćeliji ispod ovi podaci su pripremljeni u obliku indeksirane DataFrame strukture (sa skraćenim imenima):
namirnice = pd.DataFrame([
["Chleb", 250, 48.2, 8.4, 1.0],
["Bhleb", 280, 57.5, 6.8, 0.5],
["Pavlaka", 127, 4.0, 3.1, 10.5],
["Margarin", 532, 4.6, 3.2, 1.5],
["Jogurt", 48, 4.7, 4.0, 3.3],
["Mleko", 57, 4.7, 3.3, 2.8],
["Parizer", 523, 1.0, 17.0, 47.0],
["Pršuta", 268, 0.0, 25.5, 18.4],
["PilPrsa", 110, 0.0, 23.1, 1.2]])
namirnice.columns=["Namirnica", "EnergVr", "UH", "Bel", "Masti"]
namirnice1 = namirnice.set_index("Namirnica")
(a) Miloš je za doručak pojeo dva parčeta belog hleba i popio šolju mleka. Svako parče hleba je bilo namazano pavlakom i imalo je jedan šnit pršute. Kolika je energetska vrednost Miloševog doručka (u kcal), ako pretpostavimo da jedno parče hleba ima 100 g, da je za mazanje jednog parčeta hleba dovoljno 10 g premaza, da jedan šnit pršute ima 20g i da šolja mleka ima 2 dl (što je približno 200 g)?
(b) Koliko grama masti je bilo u Miloševom doručku?
(v) Prikaži dijagramom količinu ugljenih hidrata u namirnicama navedenim u tabeli.
Zadatak 5. U folderu podaci se nalazi datoteka TemperaturneAnomalije.csv koja sadrži podatke o tome za koliko stepeni Celzijusa je srednja izmerena temperatura na Zemlji veća od optimalne u poslednjih 40 godina. Ova tabela ima dva dugačka reda koji izgledaju ovako:
1977,1978,1979,1980,1981,...
0.22,0.14,0.15,0.3,0.37,...
U prvom redu se nalaze godine (1977-2017), a u drugom izmerena temperaturna anomalija. Tabela nema zaglavlje.
(a) Učitaj tabelu u strukturu DataFrame koristeći funkciju read_csv iz biblioteke pandas. (Napomena: kada tabela nema zagravlje u funkciji za učitavanje treba navesti opciju header=None.)
(b) Transponuj tabelu i koloname transponovane tabele nazovi "Godina" i "Anomalija".
(v) Indeksiraj tabelu kolonom "Godina".
(g) Prikaži temperaturne anomalije dijagramom.
Zadatak 6. U folderu podaci se nalazi datoteka StanovnistvoSrbije2017.csv (koja ima zaglavlje). Tabela ima tri kolone koje se zovu "Starost", "M" i "Ž".
(a) Učitaj datoteku u strukturu podataka DataFrame i indeksiraj tabelu kolonom "Starost".
(b) Prikaži procenjeni broj muškaraca i žena po starosti linijskim dijagramom.
(v) Na osnovu podataka iz tabele izračunaj koliki je procenjeni broj stanovnika u sledećim starosnim grupama:
- 0--17 godina,
- 18--65 godina, i
- 66 i više godina,
i predstavi ova tri podatka sektorskim dijagramom. (Uputstvo: sledeći izraz može biti od pomoći: tabela.loc["0":"17", "M":"Ž"])
Zadatak 7. U tabeli ispod su dati podaci o prodaji nekih proizvoda u pet poslovnih jedinica jedne kompanije (brojevi predstavljaju broj prodatih komada u jednom mesecu):
| Proizvod | PJ1 | PJ2 | PJ3 | PJ4 | PJ5 |
|---|---|---|---|---|---|
| Cipele | 5 | 17 | 3 | 11 | 9 |
| Košulja | 8 | 6 | 7 | 4 | 0 |
| Kaiš | 4 | 1 | 3 | 5 | 1 |
| Pantalone | 4 | 2 | 6 | 4 | 5 |
| Čarape (par) | 8 | 9 | 7 | 4 | 9 |
| Kravata | 1 | 0 | 3 | 2 | 4 |
Sledeća tabela sadrži cene ovih proizvoda u dinarima:
| Proizvod | Cena (din) |
|---|---|
| Cipele | 11.250 |
| Košulja | 6.500 |
| Kaiš | 4.750 |
| Pantalone | 2.500 |
| Čarape (par) | 750 |
| Kravata | 3.500 |
Ćelija ispod sadrži podatke iz ove dve tabele predstavljene u obliku liste:
proizvodi = [
["Cipele", 5, 17, 3, 11, 9],
["Košulja", 8, 6, 7, 4, 0],
["Kaiš", 4, 1, 3, 5, 1],
["Pantalone", 4, 2, 6, 4, 5],
["Čarape (par)", 8, 9, 7, 4, 9],
["Kravata", 1, 0, 3, 2, 4]]
cene = [
["Cipele", 11250],
["Košulja", 6500],
["Kaiš", 4750],
["Pantalone", 2500],
["Čarape (par)", 750],
["Kravata", 3500]]
(a) Predstavi obe tabele strukturom DataFrame. Indeksiraj obe tabele.
(b) Izračunaj koliko je ukupno u tom mesecu prodato cipela, košulja, kaiševa, pantalona, čarapa i kravata.
(v) Izračunaj koliko je u tom mesecu kompanija zaradila na prodaji cipela, koliko na prodaji košulja, koliko na prodaji kaiševa, itd.
(g*) Izračunaj i ispiši zaradu svake poslovne jedinice u tom mesecu.
