У овој лекцији су дати примери обраде текстуалних податка у Пајтону. Са карактерима и стринговима не могу да се изводе рачунске операције, али разне операције попут проналажења, спајања и раздвајања могу. Слично као и код нумеричких података, на крају обраде текстуалних података радимо статистику и отварамо могућности за анализу и тумачење података.
Текстуални подаци се најбоље обрађују тако што их неко прочита са разумевањем. Наравно, то људи још увек боље раде него машине. Ипак, има много ситуација када тај посао морамо да препустимо машини. На пример, када имамо десет секунди да обрадимо текст или када треба обрадити хиљаду фајлова. Помоћ машине је тада више него добродошла.
Машине могу да "читају" текст на два начина: да раде по инструкцијама или да им објаснимо шта је циљ па да саме уче. Ово друго је већ у домену машинског учења и тиме се нећемо бавити у овој лекцији. Уместо тога бавићемо се једноставнијим алгоритмима чије је исходе лакше протумачити.
Текстуални подаци са којима се најчешће сусрећемо у јавној управи су они који нису структурирани и смештени у базе података или табеле. Углавном су то документи, текстуални записи у неколико различитих формата које чувамо на разним местима. За тако организоване податке једноставних алата за обраду и анализу нема. Морамо да уложимо труд да текстови буду у формату који је машински читљив.
Текстуални подаци у табели¶
Текстуални подаци приказани у табели се лакше обрађују и анализирају него чист текст јер је неко већ разврстао делове текста и придружио их атрибутима који су описани називима колона. Ово је структура какву прижељкујемо када радимо са текстом.
За ову вежбу ћемо користити табелу која нам је већ позната -- "Општински показатељи последње стање". Учитајте је са Портала отворених података. Ако се деси да Портал не ради, учитајте исти тај фајл који је на време преузет.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#df=pd.read_csv("http://opendata.stat.gov.rs/data/WcfJsonRestService.Service1.svc/dataset/03IND01/1/csv",sep=";")
df=pd.read_csv("data/03IND01.csv",sep=";")
Шта све постоји од атрибута то можемо да видимо у заглављу помоћу функције head(). Сада ћемо изабрати погодан текстуални податак за анализу. Име председника општине изгледа као згодан податак за обраду. Проблем је само што се вредности у колони vrednost не односе увек на име председника општине. Има ту и других индикатора.
df.head()
imeiprezime=df[df['Indikator']=='Градоначелник/председник општине']['vrednost']
Да проверимо брзо шта се налази у низу imeiprezime.
imeiprezime[0]
Ово је прави тренутак да се договоримо шта хоћемо да урадимо. После ћемо видети како. Низ од 175 имена и презимена председника општине сам за себе не говори много, али би могао да нам говори на пример о родној заступљености. Ако бисмо стринг imeiprezime поделили на име и презиме, могли бисмо да направимо статистику по именима.
Ако исечемо стринг imeiprezime тамо где су размаци и узмемо први део тог исеченог стринга, добићемо само име. Функција split() сече стринг на делове. Ако не наведемо ни један аргумент, сепаратор ће бити размак. "Сечење" стринга на употребљиве делове се, иначе, стручно зове парсирање.
# пошто Пајтон низове индексира почевши од нуле, индекс 0 се односи на први елемент
imeiprezime[0].split()[0]
Сада ћемо сва имена ставити у нову листу коју ћемо назвати imena_lista. У њој ће бити само имена без презимена. Обратите пажњу да има општина за које није наведено како се зове председник општине па ту стоји размак " ". Оваква имена треба прескочити. Написаћемо програм који пролази кроз сва имена у листи, проверава да ли су различита од " " и прави нову листу без недостајућих имена. Петља у програму за сваки елемент iip који се налази у листи imeiprezime проверава да ли је једнак " ". Ако није, стринг делимо на мање стрингове одвојене размаком iip.split(), узимамо само први део у ком се налази име и тим елементом допуњујемо нову листу imena_lista помоћу функције append(). Услов iip!=" " значи да елемент iip није једнак " ". (Запамтите да код логичких исказа знак != значи није једнако, док је == једнако.)
imena_lista=[]
for iip in imeiprezime:
if iip!=" ":
imena_lista.append(iip.split()[0])
imena_lista
Библиотека pandas има променљиву типа серија која је сложенија варијанта листе. За тај тип променљиве су написане бројне функције које не постоје за листе. Зато је згодно да imena_lista уместо листе постане серија. У том случају ће нам одмах бити доступне разне статистичке функције. Листу ћемо у серију претворити помоћу функције Series() и одмах пребројати колико има којих имена.
# од листе правимо серију како бисмо лакше могли да пребројимо имена
imena_serija=pd.Series(imena_lista)
imena_serija.value_counts()
Изгледа да је са серијом све у реду. Видимо да има 95 различитих имена. Сада ћемо графички да прикажемо која се имена колико пута помињу у серији. Због прегледности приказујемо само првих 16 најчешћих, али то лако можете да промените. Са серијама се лако ради цртање графика. У овом случају у серију y стављамо имена сортирана по броју појављивања. Довољно је да напишемо y.plot() и график ће се приказати. Додуше, избор типа графика неће бити баш најбољи. Због тога треба спецификовати да хоћемо хоризонтални стубични дијаграм, тј. horizontal bar chart - kind='barh'. Да бисмо променили редослед најчешћих имена тако да иде одозго на доле, инвертоваћемо у-осу помоћу gca().invert_yaxis().
y=imena_serija.value_counts()[:16]
y.plot(kind='barh')
plt.xlabel('Број председника општина са тим именом')
plt.gca().invert_yaxis()
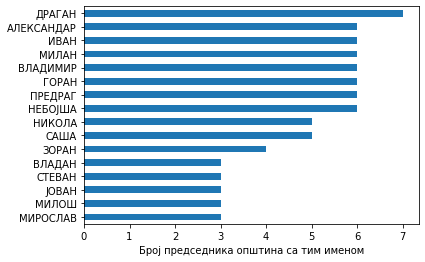
Ово је једноставан и прегледан начин да упоредимо резултате. Одмах видимо да је најчешће неки Драган председник општине, па Владимир, па Милан итд. . Примећујете ли нешто необично код ових имена? Сва су мушка. Има ли уопште председница општина у Србији. Колико?
Пошто у серији немамо податак о полу председника општина већ само име, требало би да на основу имена проценимо ког су пола. Рачунар не зна које је име мушко, а које женско. Направићемо процену на основу хеуристике (једноставног правила које углавном даје тачну процену). Једна таква хеуристика може да буде да се женска имена скоро увек завршавају на А.
Код сваке речи ћемо узети последње слово и проверити да ли је А. Појединачне карактере из текста у Пајтону можемо да издвајамо уз помоћ индекса у угластој загради. Тако ће нам ime[0] дати прво слово, док ће нам ime[-1] дати последње. У низ pol ћемо ставити 0 за имена која се не завршавају на А и 1 за она која се завршавају тим словом.
* Важна напомена! Када проверавате које је које слово обавезно обратите пажњу на писмо. "А" и "А" нису исти карактер ако је једном слово писано латиницом, а други пут ћирилицом.
pol=[]
for ime in imena_lista:
if ime[-1]=="А":
pol.append(1)
else:
pol.append(0)
Пошто у серији имамо само нуле и јединице, средња вредност низа ће нам рећи колики је удео јединица (односно имена која се завршавају на А) у целом низу.
# удео јединица у низу
np.mean(pol)
Чини се да имамо 25% председника општина чија се имена завршавају на А. Да ли су сви жене? Вероватно не. Хајде да првo направимо DataFrame са две колоне: један са именом, друга са кôдом који одговара процењеном полу.
Овде ћемо DataFrame направимо помоћу структуре речник (енг. dictionary). Нећемо се на томе много задржавати. Пробајте да варирате садржај у следећој ћелији да видите како то функционише. У сваком случају, овде смо одређеним ознакама (Ime и Pol), придружили низове imena_lista и pol. Помоћу функције DataFrame() Пајтон ће садржај речника data спаковати у DataFrame где су ознаке називи колона, а низови садржај тих колона.
data={'Ime':imena_lista,'Pol':pol}
ime_df=pd.DataFrame(data)
ime_df
Сада да видимо сва имена којима је додељен кôд 1.
ime_df[ime_df['Pol']==1]['Ime']
Видимо да једноставна хеуристика, односно алгоритам који смо од ње направили имена као што су Небојша, Саша, Никола итд. такође разврстава као женска. Срећом нема их превише па можемо да их ставимо у низ изузетака и тако променимо кôд. Истина ни ми не знамо поуздано ког су пола Сања, Саша или Владица, али то неће много утицати на коначни резултат. Нас интересује процена.
У for петљи по свим именима из списка изузетака одговарајућим именима ћемо додељивати кôд 0.
for ime in ['НЕБОЈША','САША','НИКОЛА','МАЛИША','СИНИША','ЈОВИЦА','СТЕВА','АНДРИЈА','ДОБРИЦА']:
ime_df.loc[ime_df['Ime']==ime,'Pol']=0
Да видимо сад колико има јединица у низу, односно председница међу председницима.
np.mean(ime_df['Pol'])
Има их, изгледа, 11%. Графички то можемо да прикажемо овако:
# графички то може да изгледа овако
plt.figure(figsize=(5,5))
plt.pie(ime_df['Pol'].value_counts(), labels=['М','Ж'],colors=['blue','red'])
plt.show()
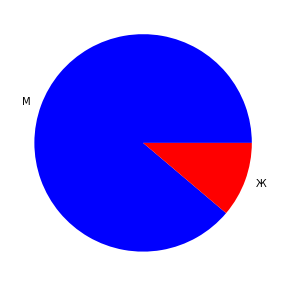
Чувена "питица" се црта уз помоћ функције pie(). Ево шта смо учинили са се она појави. Прво смо помоћу функције figure() задали димензије графикона од 5 пута 5 инча: figsize=(5,5). У следећем кораку смо пребројали колико има којих вредности у ime_df['Pol'] помоћу функције value_counts(). Пошто имамо само две различите вредности (0 и 1, односно мушко и женско), придружили смо им ознаке М и Ж и боје плаво и црвено. Са тим аргументима смо покренули функцију за цртање питица. Коначно, у последњем реду стоји наредба show() да се графикон прикаже на екрану.
Претрага текста¶
Текст није увек сложен у табеле, нити у листе где је сваки елемент стринг у ком прво иде име, па размак па презиме. Текстови немају унапред познату структуру. Зато је често неопходно да у тексту тражимо стринг.
Претрага текста може да буде произвољно компликована. За то постоје посебне библиотеке којима се овде нећемо бавити. За доста тога довољне су функције за рад са стринговима које Пајтон већ има. Навешћемо само неколико корисних функција.
Функција count() пробројава стингове у тексту. Тај стринг може да буде нпр. размак " ". Ако пребројимо размаке знаћемо колико има речи у тексту.
tekst='Претрага текста може да буде произвољно компликована. За то постоје посебне библиотеке којима се овде нећемо бавити. За доста тога довољне су функције за рад са стринговима које Пајтон већ има. Навешћемо само неколико корисних функција.'
tekst.count(" ")
Помоћу функције split() можемо да поделимо текст на листу стрингова које одваја аргумент те функције. Видели смо како то ради кад смо раздвајали име и презиме. Слично можемо и да поделимо текст на реченице.
tekst.split(". ")
Помоћу функције find() можемо да нађемо где се налази одговарајући стринг. Резултат ће бити индекс, односно редни број карактера у тексту где почиње тај стринг минус један.
tekst.find("библиотеке")
Помоћу функција upper() и lower() можемо да претварамо слова у велика и мала. То може да буде згодно код екстракције кључних речи где нам није битно каквим је словима записан термин. Замену текста неким другим можемо да урадимо помоћу функције replace(). Ево примера:
tekst.replace("произвољно", "произвољно".upper())
Пошто је игра са стринговима заиста произвољно компликована, даље испитивање ових функција препуштамо вашем самосталном раду. Уместо тога, прелазимо на статистику стрингова.
Статистика токена¶
Анализа текста се заснива на статистици токена (знакова) у том тексту. Тај токен може да буде слово, слог, реч, синтагма итд. Сваки текст у дигиталном облику можемо да поделимо на токене и да их онда статистички обрађујемо. Уколико текст није чист (plain text) него има и контролне знакове, то неће бити сасвим једноставно. Врло често је неопходно да текст чистимо неколико пута како би био адекватан за анализу. Да погледамо сада како би изгледала једноставна анализа овог пасуса.
Једноставна машинска анализа текста подразумева чишћење текста (уклањање знакова интерпункције, уклањање речи ко праве шум, конверзија свих слова у мала, итд.) и "токенизацију" очишћеног текста, тј. раздвајање текста на појединачне токене. Иако би било добро прво да очистимо текст па да га токенизујемо, то није увек једноставно.
Пробаћемо како изгледа анализа на првом пасусу овог текста. Намерно ћемо овог пута прво урадити токенизацију па тек онда чишћење текста.
pasus="Анализа текста се заснива на статистици токена (знакова) у том тексту. Тај токен може да буде слово, слог, реч, синтагма итд. Сваки текст у дигиталном облику можемо да поделимо на токене и да их онда статистички обрађујемо. Уколико текст није чист (plain text) него има и контролне знакове, то неће бити сасвим једноставно. Врло често је неопходно да текст чистимо неколико пута како би био адекаватан за анализу. Да погледамо сада како би изгледала једноставна анализа овог пасуса."
У најједноставнијем случају, токени су појединачни карактери у тексту. То ћемо прво да пробамо. Направићемо листу токена (у овом случају знакова) који се налазе у том пасусу. Отворићемо на почетку празну листу pasus_lista и потом додавати знак по знак у листу док не дођемо до краја пасуса.
pasus_lista=[]
for slovo in range(0, len(pasus)):
pasus_lista.append(pasus[slovo])
print(pasus_lista)
Статистику ове листе ћемо лакше урадити ако је пребацимо у променљиву типа серија коју имамо у Pandas библиотеци. За податке тог типа имамо неколико статистичких функција. Једна од њих је describe која нам даје основну дескриптивну статистику: колико серија има елемената (count), колико их има јединствених (unique), који се најчешће појављују (top) и колико пута (freq).
pasus_serija=pd.Series(pasus_lista)
pasus_serija.describe()
У тексту који смо обрадили има 482 знака, од чега 44 јединствена. Иако изгледа да нема знака који се најчешће понавља, има га -- то је размак. Понавља се 75 пута. Коначно, pasus_serija спада у објекте.
Ова статистика нам не говори много о тексту. Зато би било боље да погледамо статистику свих знакова, односно да их пребројимо. Функција value_counts ради управо то. При томе ова функција сортира елементе почевши од најфреквентнијег.
pasus_serija.value_counts()
Најчешће се појављује " " (77 пута), па "а" (50), па "о" (43) итд. Ако прођете кроз целу листу видећете да се посебно појављују велика и мала слова, као и да ту има и знакова интерпункције. За фреквенцијску анализу слова није много важно колико се пута појављују заграде и да ли је слово на почетку реченице. Поједностављену анализу можемо да урадимо тако што ћемо написати нашу функцију ciscenje() која прво сва слова претвори у мала уз помоћ функције lower, замени све знаке интерпункције ",.,()_" размацима помоћу функције replace и коначно избрише вишак размака тамо где их има помоћу функције strip().
Уклањање знакова који нису слова може ефикасније да се уради помоћу регуларних израза (regular expressions), али ћемо то оставити за напредни курс.
def ciscenje(text):
text=text.lower()
text=text.replace(',', ' ')
text=text.replace('.', ' ')
text=text.replace('(', ' ')
text=text.replace(')', ' ')
text=text.replace('_', ' ')
text=text.strip()
return text
ciscenje(pasus)
Приметите како смо све кораке чишћења текста ставили у једну функцију и тако аутоматизовали овај процес. То је суштина скриптне обраде података. Кад коначно напишемо кôд, онда све можемо да извршимо у једном кораку.
Сад можемо да поновимо токенизацију, односно прављење листе токена са овако поједностављеним текстом и да онда израчунамо фреквенције.
pasus=ciscenje(pasus)
pasus_lista=[]
for znak in range(0, len(pasus)):
pasus_lista.append(pasus[znak])
pasus_serija=pd.Series(pasus_lista)
pasus_serija.value_counts()
Чему би сад ово могло да послужи? На пример за препознавање језика на ком је писан текст. Фреквенција слова се значајно разликује међу језицима па чак и међу дијалектима. Несумњиво je да ће фреквенција слова ј бити већа у јекавици него у екавици. Чак и кратке секвенце слова могу да укажу на језик којим је текст писан и за то не морамо да знамо језик. Машинама је довољно да низове фреквенци у некој реченици упореде са типичним фреквенцама у одређеним језицима и тако одреде који је језик у питању. У енглеском је, на пример, најфреквентније слово е, док је у српском а. Јасно, уколико постоје специфична слова као што су ћ, я или Ψ идентификација ће бити тривијална. Машине су нам потребне за оно што није очигледно.
n-грам¶
Јасно, фреквенције слова не могу много да нам кажу о садржају текста. Боље је да пробамо са статистиком речи. Основни концепт у рударењу текста је n-грам, тј. секвенцa од n токена (најчешће знакова или речи) у неком већем тексту. Ако за токен узмемо реч, 1-грами су у овом тексту "Основни", "концепт", "у" итд., док су 2-грами "Основни концепт", "концепт у" итд.
Да бисмо видели моћ статистичке анализе токена, узећемо један (вама) непознати текст и анализирати га. Тај текст је мало већи и налази се у фајлу "CELEX 32016R0679 EN TXT.txt". Нећемо га учитавати у DataFrame као што смо то радили са табелама. Довољно је да га учитамо у променљиву типа стринг.
text=open('data\CELEX 32016R0679 EN TXT.txt').read()
type(text)
Да видимо прво шта се налази на почетку овог текста.
text[:200]
Изгледа, да овде имамо разних контролних кодова и тагова које треба уклонити. На основу ове кратке секвенце чини се да су тагови одвојени од речи у тексту. То би могло да нам помогне у чишћењу. Да видимо како би сада изгледало први неколико токена.
text.split()[:15]
# број токена
len(text.split())
Постоји функција isalpha() која нам говори да ли је стринг обичан текст или не. То бисмо могли да искористимо и елиминишемо све што није текст. На пример, први токен из горње листе јесте текст док други није. Да видимо како то изгледа за први 15 токена.
for i in range(15):
print(text.split()[i].isalpha(),'\t',text.split()[i])
Оваква елиминација вероватно неће радити 100% тачно јер постоје полусложенице, неке речи су под наводницима, имамо алфанумеричке комбинације (слова и цифре заједно) итд. Свеједно, биће довољно добро за вежбу. Водећи се логиком да оно што није обичан текст треба избацити направићемо нову листу у којој ће бити само речи.
reci=[]
for token in text.split():
if token.isalpha():
reci.append(token)
len(reci)
reci[:15]
Издвајањем најфреквентнијих речи требало би да стекнемо утисак о чему је овај текст.
pd.Series(reci).value_counts()
Ово сада већ личи на озбиљну статистику речи. Међутим, из ових неколико редова, ипак, не можемо да кажемо о чему је текст. Текст је очигледно на енглеском језику и најчешће речи су the, of, to итд. Те најчешће речи су уобичајене за било који текст и неће нам много помоћи да проникнемо у суштину текста. Мораћемо да уклонимо те опште речи да бисмо дошли до оних информативнијих. У терминологији обраде података те речи којих има свугде, а не доприносе разумевању текста се зову stop words.
Облак речи¶
Статистика токена може да се прикаже графички. Тај начин приказа се зове облак речи (енг. word cloud). Стандардне библиотеке не знају да га прикажу. Требаће нам једна посебна: wordcloud. Ако није инсталирана у вашем окружењу, потребно је да је инсталирате са pip install wordcloud.
from wordcloud import WordCloud
Библиотека wordcloud није само за графичко приказивање. Она има функције које раде много тога што нам је потребно за анализу текста. Функција wordcloud() зна да елеминише све што није чист текст, зна шта су stop words и како да их елиминише. Штавише, зна да издвоји као посебне токене комбинације од две речи које се често појављују у тексту.
Ми ћемо само да пребацимо сва слова у мала се токени не би непотребно раздвајали.
text=text.lower()
Као аргументе за функцију WordCloud() ћемо ставити collocation_threshold=3 што значи да не тражи n-граме веће од три речи, min_word_length=3 да игнорише речи краће од три слова и max_words=300 да ограничи број речи на 300. Остала два аргумента одређују величину слике.
wordcloud = WordCloud(collocation_threshold=3,min_word_length=3,
width=1000, height=600, max_words=300).generate(text)
Коначно, да прикажемо графикон. Кад га Пајтон исцрта, предлажем да га отворите у посебном прозору како бисте видели целу слику.
plt.figure(figsize=(14,10))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off");

wordcloud.to_file("GDPR wordcloud.png")
Шта видите на графикону? Најчешће коришћени термини су лични подаци (personal data), заштита података (data protection), физичко лице (natural person), земља чланица (member state) итд. Шта мислите о чему је текст? У питању је GDPR, директива Европске уније која се тиче заштите података о личности.
Иако се обрада текстуалних података не бави смислом текста, пажљива анализа садржаја на нивоу статистике токена лако може да обради велики текст и прикаже најважније елементе. Наравно, у анализи може да се иде даље. Први корак даље се назива процесирање природног језика или NLP (енг. Natural Language Processing). О томе ће, вероватно, бити више речи у неком наредном, напредном курсу.