10. Džupajter i Eksel¶
U ovoj lekciji ćemo govoriti o:
- odnosu Džupajtera i Eksela;
- o učitavanju podataka iz Eksel datoteke; i
- o upisivanju podataka u Eksel datoteku.
10.1. Zašto Džupajter, a zašto Eksel¶
Majkrosoftov Eksel (Microsoft Excel) predstavlja jedan od najrasprostranjenijih softverskih proizvoda za obradu tabelarno predstavljenih podataka. Eksel svoju popularnost duguje tome što je tabela u koju se unose podaci "opipljiva", ona je tu, korisnik može samo da klikne na polje i da unese podatak ili formulu. Prirodno se nameće pitanje zašto ovaj kurs nije organizovan oko Eksela. Razloga ima mnogo, a navešćemo nekoliko najvažnijih.
Cena. Za razliku od Eksela koji je komercijalni proizvod i koji mora da se kupi da bi mogao legalno da se koristi, Pajton, sve njegove biblioteke i Džupajter (kao radno okruženje za Pajton) su besplatni. Svako može bez ikakve naknade da instalira Pajton i Džupajter i da ih koristi za lične potrebe i za obrazovne potrebe.
Obrada podataka putem jasno vidljive procedure. U ćelije Eksel tabele se, pored teksta i brojeva, mogu uneti i formule. Na taj način se u Ekselu može postići sve o čemu smo mi ovde pisali. Problem sa ovakvim pristupom nastaje kada pokušavamo da shvatimo šta tabela u koju je neko već uneo formule radi i kako to ona radi. U velikim tabelama nije lako ustanoviti koja formula zavisi od koje ćelije i, uopšte, kojim redom će se formule izračunavati. Dakle, lako je podeliti sa saradnicima Eksel tabelu koja će odraditi posao, ali nije lako podeliti sa saradnicima proces koji ta tabela implementira. S druge strane, ako su podaci obrađeni upotrebom nekog skript-jezika kao što je Pajton, iz samog programa (i komentara u njemu!) se može rekonstruisati proces obrade podataka. Na taj način saradnici na projektu mogu da provere proces obrade podataka i tako lakše uoče eventualne greške u proceduri obrade podataka. Osim toga, ako je potrebno izvršiti novi račun koji je sličan postojećem lakše je prilagoditi eksplicitan kod.
Fleksibilnost. Pajton dolazi sa veoma velikim brojem biblioteka koje su razvijane za potrebe efikasne obrade velikih količina podataka. Sve te biblioteke su dostupne iz Džupajtera. Ako se za koju godinu pojavi neka nova biblioteka koja nudi nove mogućnosti, možemo je lako i brzo uvesti u Džupajter i koristiti. Za razliku od Pajtona, nove funkcionalnosti Eksela se ne distribuiraju kroz biblioteke funkcija (koje se lako dodaju sistemu), već svaka nova funkcionalnost iziskuje instalaciju nove verzije celog programa.
Obrada podataka putem jasno navedenih kratkih programa (koji nisu deo tabele!) predstavlja najfleksibilniji način obrade podataka i predstavlja okosnicu svakog ozbiljnog sistema za obradu podataka. Zato je važno da se svi sretnemo sa programiranjem, čak iako ne planiramo svi da budemo programeri!
10.2. Učitavanje podataka iz lokalnih Eksel datoteka¶
Majkrosoftov Eksel (Microsoft Excel) predstavlja jedan od najrasprostranjenijih softverskih proizvoda za obradu tabelarno predstavljenih podataka. Biblioteka pandas zato ima funkciju koja može da učita podatke predstavljene Eksel tabelom.
Struktura Eksel dokumenta je relativno složena jer u jednom dokumentu može da se nalazi više tabela. Jedan Eksel dokument se, zato, sastoji iz nekoliko radnih listova (engl. work sheets):
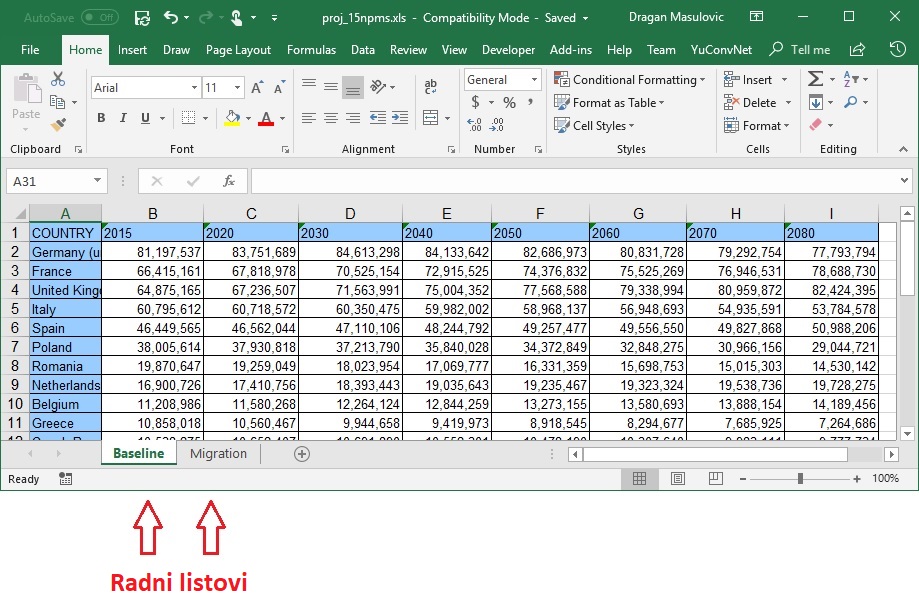
pa funkciji za učitavanje Eksel tabele pored imena datoteke treba dati i ime radnog lista sa koga se učitava tabela. Ukoliko se ne navede ime radnog lista funkcija će učitati tabelu iz prvog radnog lista na koji naiđe. Ovo obično koristimo samo u situacijama kada smo sigurni da Eksel radna sveska ima samo jedan radni list.
Sada ćemo iz datoteke Aditivi.xlsx koja se nalazi u folderu podaci učitati tabelu iz (jedinog) radnog lista "Aditivi":
import pandas as pd
aditivi = pd.read_excel("podaci/Aditivi.xlsx", sheet_name="Aditivi")
Ova datoteka sadrži podatke o aditivima, što su supstance koje se koriste u industriji. Neki od njih se koriste i u industriji hrane. (Podaci su preuzeti iz udžbenika biologije za 8. razred.)
Evo prvih nekoliko redova tabele:
aditivi.head(15)
Vidimo da su ćelije koje su bile prazne u Eksel tabeli ovde dobile specijalnu vrednost NaN što je skraćenica od not a number (engl. "nije broj"). Ovo je specijalna vrednost koja se koristi da se otkriju potencijalne greške koje mogu da nastanu prilikom učitavanja velikih tabela. U našem slučaju prazne ćelije u koloni "Napomena" i treba da ostanu prazne, pa ćemo tabelu učitati ponovo, s tim da ćemo "zamoliti Pajton da isključi veštačku inteligenciju":
aditivi = pd.read_excel("podaci/Aditivi.xlsx", sheet_name="Aditivi", na_filter=False)
aditivi.head(15)
Argument na_filter=False kaže funkciji read_excel da prazne ćelije ostanu prazne i da u njih ne unosi vrednost NaN.
Napravićemo sada frekvencijsku analizu ove tabele na osnovu štetnosti aditiva.
aditivi["Štetnost"].value_counts()
Profiltriraćemo tabelu da bismo izlistali aditive koji mogu izazvati rak.
aditivi[aditivi.Napomena == "može izazvati rak"]
Za kraj, izlistaćemo aditive koji su izuzetno opasni ili mogu izazvati rak. U tu svrhu treba da kombinujemo dva kriterijuma:
Napomena == "može izazvati rak" ili Štetnost == "IZUZETNO OPASAN"
Logički veznik "ili" se u biblioteci pandas označava simbolom |. Prema tome, podatke dobijamo tako što tabeli prosledimo sledeći zahtev za filtriranje:
aditivi[(aditivi.Napomena == "može izazvati rak") | (aditivi.Štetnost == "IZUZETNO OPASAN")]
10.3. Upisivanje tabele u Eksel datoteku¶
Bilo koju tabelu možemo da upišemo i u Eksel datoteku kao što smo ih upisivali u CSV datoteke. Potrebno se samo pozvati funkciju to_excel i proslediti joj ime datoteke. Na primer, ako je opasni_aditivi tabela koja sadrži spisak opasnih aditiva:
opasni_aditivi = aditivi[(aditivi.Napomena == "može izazvati rak") | (aditivi.Štetnost == "IZUZETNO OPASAN")]
nju možemo upisati u Eksel datoteku ovako:
opasni_aditivi.to_excel("podaci/opasni_aditivi.xlsx", encoding="utf-8")
Argument encoding="utf-8" moramo da prosledimo funkciji zato što u tabeli imamo podatke koji su zapisani ćirilicom, kao što je bio slučaj kod pisanja u CSV datoteke. Ako sada otvorimo ovu datoteku iz Eksela dobićemo ovakav izgled:
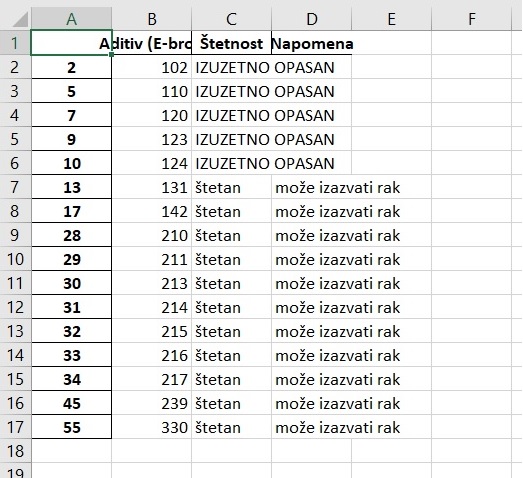
Vidimo da je Pajton upisao i indeksnu kolonu što nam u ovom slučaju ne odgovara. Kao i kod upisivanja u CSV datoteke možemo reći Pajtonu da u datoteku ne upisuje indeksnu kolonu tako što ćemo navesti još i argument index=False:
opasni_aditivi.to_excel("podaci/opasni_aditivi.xlsx", encoding="utf-8", index=False)
Ako sada novu datoteku učitamo iz Eksela dobijamo
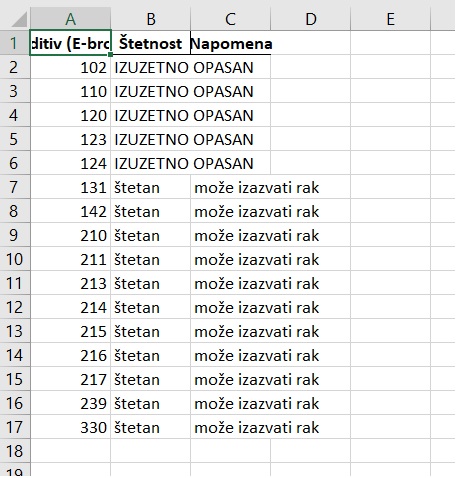
Za kraj treba još malo proširiti kolone u Eksel tabeli da bi se ulepšao njen izgled -- i gotovo!.
10.4. Zadaci¶
Zadatke reši u Džupajteru.
Zadatak 1. Pogledaj pažljivo naredbe u sledećoj ćeliji, pa odgovori na pitanja:
import pandas as pd
aditivi = pd.read_excel("podaci/Aditivi.xlsx", sheet_name="Aditivi", na_filter=False)
- Šta će uraditi funkcija
read_excelako se ukloni argumentsheet_name="Aditivi"(znamo da tabela ima samo jedan radni list)? - Šta znači argument
na_filter=Falsefunkcijeread_excel?
Zadatak 2. U tabeli podaci/SO2.xlsx nalaze se rezultati merenja koncentracije sumpor-dioksida u 2017. godini u nekim gradovima Srbije. Tabela ima četiri kolone:
- MernaStanica = Merna stanica
- SGV = Srednja godišnja vrednost u mikrogramima po kubnom metru
- BD125 = Broj dana sa više od 125 mikrograma po kubnom metru
- MDV = Maksimalna dnevna vrednost u mikrogramima po kubnom metru
(a) Učitaj ovu tabelu u strukturu podataka DataFrame.
(b) Sortiraj podake po koloni MDV i prikaži vrednosti u ovoj koloni histogramom.
(v) Izdvoj iz tabele one redove kod kojih je vrednost u koloni BD125 veća od 0 i tako dobijenu tabelu upiši u novu datoteku podaci/SO2-VisokeVrednosti.xlsx vodeći računa o tome da tabela sadrži slova specifična za srpski jezik.
Zadatak 3. U tabeli podaci/Razred.xlsx nalaze se ocene učenika jednog razreda iz informatike. Podaci su realni, pa su zato anonimizirani (imena učenika su Učenik 1, Učenik 2, itd). Tabela ima zaglavlje, a tekst je unet latiničnim pismom.
(a) Učitaj ovu tabelu u strukturu podataka DataFrame i prikaži prvih nekoliko redova da razumeš strukturu tabele.
(Kolone označene sa "K" predstavljaju ocene iz kontrolnog zadatka, kolone označene sa "P" predstavljaju ocenu iz pismenog zadatka (ovo je latinično slovo P), kolone označene sa "U" predstavljaju ocenu iz usmene provere, a kolona "D" ocenu iz domaćih zadataka.)
(b) Indeksiraj tabelu kolonom "Ime".
(v) Izračunaj i ispiši prosečnu ocenu na svakom od tri pismena zadatka (kolone "P1", "P2" i "P3").
(g) Dodaj tabeli novu kolonu "Prosek" i onda za svakog učenika izračunaj prosek ocena i upiši dobijenu vrednost u ovu kolonu tabele.
(d) Dodaj tabeli novu kolonu "Ocena" i onda za svakog učenika izračunaj zaključnu ocenu na osnovu proseka, i upiši tu ocenu u ovu kolonu tabele. Sledeća funkcija ti može biti korisna:
def zaklj_ocena(prosek):
if prosek >= 4.50:
return 5
elif prosek >= 3.50:
return 4
elif prosek >= 2.50:
return 3
elif prosek >= 1.50:
return 2
else:
return 1
(d) Dobijenu tabelu upiši u novu datoteku podaci/Razred-Ocene.xlsx vodeći računa o tome da tabela sadrži slova specifična za srpski jezik.
Zadatak 4. Eurostat je zvanična organizacija Evropske unije koja se bavi statističkim analizama od značaja za rad i razvoj unije. Svi podaci koje Eurostat prikupi i obradi su javno dostupni na linku https://ec.europa.eu/eurostat/data/database
U datoteci podaci/EUProjPop.xlsx se nalaze podaci o očekivanom broju stanovnika EU do 2080. godine. Ova tabela ima dva radna lista: Baseline na kome se nalaze podaci o očekivanom broju stanovnika, i Migration na kome se nalaze podaci o očekivanom broju stanovnika u slučaju povećanog broja migranata u zemlje Evropske unije.
(a) Učitaj ove dve tabele u dve strukture podataka DataFrame i za svaku prikaži prvih nekoliko redova da razumeš strukturu tabela.
(b) Obema tabelama dodaj novu vrstu "EU", pa za svaku tabelu izračunaj i u tu vrstu upiši ukupan očekivani broj stanovnika EU za svaku od navedenih godina.
(v) Tabeli koja je nastala učitavanjem radnog lista Migration dodaj novu vrstu "Migration" pa u nju upiši očekivani priraštaj broja stanovnika u EU usled migracije po godinama (to je razlika podatka u vrsti "EU" tabele "Migration" i odgovarajućeg podatka u vrsti "EU" tabele "Baseline").
(g) Prikaži linijskim dijagramom očekivani priraštaj broja stanovnika u EU usled migracije po godinama.
(d) Tabeli koja je nastala učitavanjem radnog lista Baseline dodaj novu vrstu "EU-UK", pa izračunaj i u tu vrstu upiši ukupan očekivani broj stanvnika EU za svaku od navedenih godina bez stanovnika Velike Britanije.
(đ) Tabelu dobijenu na ovaj način upiši u datoteku podaci/EU-UK.xlsx
Zadatak 5. U tabeli podaci/Cricket.xlsx se nalaze podaci o najboljim igračima kriketa. Ova tabela ima zaglavlje.
(a) Učitaj ovu tabelu u strukturu podataka DataFrame i ispiši prvih nekoliko redova tabele da vidiš kako izgleda. Indeksiraj tabelu kolonom "Player".
(b) Dodaj tabeli novu kolonu "YP" (Years Played) i u nju upiši koliko godina je svaki igrač bio aktivan. (Za svakog igrača od godine u koloni "To" oduzeti godinu u koloni "From").
(v) Dodaj tabeli novu kolonu "ARY" (Average Runs per Year) i u nju upiši količnik brojeva iz kolone "Runs" i "YP". (ARY = Runs / YP).
(g) Sortiraj tabelu po koloni "ARY" od najvećih ka najmanjim vrednostima i prikaži prvih 25 redova tabele. U kom veku su bili aktivni skoro svi od ovih 25 igrača? Šta misliš zašto?
