У овој лекцији је приказано како се обрађују бројчани подаци у табелама. За разлику од текстуалних података, са бројевима можемо да рачунамо и зато је велики број Пајтон функција резервисан за нумеричке податке. Треба обратити пажњу да нису сви бројчани подаци истог типа и да функције могу да буду осетљиве на ту разлику. То што је нама "очигледно" који је тип података у питању, не мора да значи да су подаци до краја чисти и да Пајтон то препознаје.
Пајтон, у својим библиотекама, има мноштво функција за обраду и експлоративну анализу нумеричких података. Уколико је колона у табели чиста и не садржи ништа сем бројева, највећи део уводних анализа можемо да урадимо са врло мало труда.
Да бисмо на располагању имали потребне функције, учитаћемо на почетку три библиотеке: pandas (за рад са табелама), numpy (за рад са нумеричким подацима) и matplotlib.pyplot и seaborn (за цртање графикона).
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
Уколико нису све библиотеке инсталиране, потребно је да их инсталирате, нпр. као pip install seaborn.
За потребе вежбања, учитаћемо једну табелу са Националног портала отворених података (Општински показатељи последње стање) која садржи и текстуалне и бројчане податке. За случај да учитавање преко интернета не ради, учитаћемо је из директоријума .\data.
#df=pd.read_csv("https://data.gov.rs/sr/datasets/r/b1f1f94a-fe21-3a2a-b801-6f0f05b24257",sep=";")
opps=pd.read_csv("data/03IND01.csv",sep=";")
opps
Евидентно, у табели имамо различите индикаторе (показатеље) по општинама и годинама који су распоређени на начин који није најзгоднији. Ова огромна табела (има 13246 редова) изгледа као колекција истих табела за појединачне индикаторе. Видимо да ту, на пример, постоји индикатор Површина (у km²), али тај податак не може лако да се обради јер су вредности тог индикатора стављене у колону vrednost са мноштвом других података различитог типа. Када бисмо хтели да нађемо укупну површину свих општина, то не може без додатне обраде података.
Да погледамо за почетак, које типове података овде имамо.
opps.dtypes
Месец, година и матични број општине су типе integer, док су сви остали сложени. Да бисмо ишта могли да анализирамо, мораћемо да издвојимо под-табеле за конкретне показатеље. Које показатеље овде уопште имамо видећемо коришћењем функције unique() за податке у колони Indikator.
opps['Indikator'].unique()
Једнодимензионални скупови података¶
За једноставне анализе је довољно да извучемо само један индикатор који нас интересује. Примера ради, сада ћемо извући само индикатор везан за површину општине.
povrsina=opps[opps['Indikator']=='Површина (у км²)']
povrsina.head()
Изгледа да су сада у колони vrednost само бројеви. Можемо онда да их саберемо и видимо колика је површина свих општина у Србији заједно.
povrsina['vrednost'].sum()
Упс! Ово нисмо очекивали. Уместо суме бројева, добили смо суму стрингова, тј. спојене вредности свих стрингова у колони vrednost од '387', '707' па редом. Изгледа да Пајтон и даље не зна да су у колони vrednost бројеви.
povrsina.dtypes
Да, Пајтон је задржао тип променљиве који смо имали у оригиналној табели. То треба да променимо помоћу функције astype(). Тако ћемо Пајтону објаснити да подаци у колони vrednost треба да буду типа float.
povrsina = povrsina.astype({'vrednost':float})
povrsina.dtypes
povrsina['vrednost'].sum()
Ово делује у реду. Толика је површина Србије.
Сада ћемо обрадити један други нумерички индикатор, просечну нето зараду. Тај индикатор се зове тачно Просечна нето зарада за месец, према општини пребивалишта запослених.
neto_zarada=opps[opps['Indikator']=='Просечна нето зарада за месец, према општини пребивалишта запослених']
С обзиром да нам за нумеричку анализу табеле neto_zarada нису потребне све колоне, задржаћемо само три. Матични број задржавамо само због контроле.
neto_zarada=neto_zarada[['idter','nter','vrednost']]
neto_zarada = neto_zarada.astype({'vrednost':float})
Ако желимо да видимо где су у Србији просечне зараде највеће, потребно је да сортирамо табелу према вредности. Сортирање не мења вредности у табели већ нам приказује податке на начин који нама одговара.
neto_zarada.sort_values('vrednost',ascending=False).head(10)
Највеће зараде су, очигледно, у Београду. Прва општина на овој листи која није београдска је Костолац.
Када бисмо помоћу функције max() тражили општину са највећим зарадама, то би изгледало овако:
neto_zarada[neto_zarada.vrednost==neto_zarada.vrednost.max()]
Функцију max можемо да применимо и на целу табелу, али ће нам тад излаз бити низ максималних вредности по колонама. То нам сад није посебно корисно. Приметите да максимум за нумеричке и текстуалне вредности ради другачије. У првом случају тражи највећу вредност, а у другом податке поређа лексикографски па прикаже последњи у низу.
neto_zarada.max()
Ако цео низ бројева због скраћеног приказа или комуникације морамо да сведемо на један број, онда је најбоље узети једну од мера просека: средњу вредност или медијану. Максимална или минимална вредност зарада су куриозитети и не говоре нам много о целом скупу. Средња вредност нам више говори о томе колике су зараде у Србији дајући нам аритметичку средину. Медијана нам даје просек на мало другачији податак, она нам даје типичну вредност зараде, односно колику зараду имају они који су на средини листе о висини зараде. Код симетричних расподела података, средња вредност и медијана се поклапају, али расподела зарада није таква. Увек има више оних са малим зарадама и неколико оних са веома великим. То се врло често злоупотребљава. Већина људи има мање зараде од средње вредности. Кад год је новац у питању, средња вредност буде већа од медијане.
Пајтон нема функцију за средњу вредност у основном окружењу па је потребно учитати библиотеку statistics да бисмо имали функцију mean. Срећом, средња вредност се лако рачуна -- само треба поделити збир свих елемената са њиховим бројем. (Ако вам је лакше учитајте библиотеку па користите mean.)
neto_zarada['vrednost'].sum()/neto_zarada['vrednost'].size
neto_zarada.vrednost.median()
Видимо да средња вредност просечне нето зараде по општинама за више од две хиљаде динара већа него медијана.
Дескриптивна анализа¶
Рекли смо раније да се у овом курсу нећемо бавити (озбиљном) анализом података јер она подразумева стручно, доменско знање. Дескриптивна анализа је више дескрипција него анализа. Њу рачунар ради по алгоритму и приказује нам мере централне тенденције и мере растура за одређени скуп података. Тај део посла не захтева било какво доменско знање. Тумачење мера које нам даје дескриптивна анализа је већ нешто друго.
Дескриптивна анализа даје главне мере једног скупа бројчаних података као што су број елемената (count), средња вредност (mean), стандардна девијација (std), минимум (min) итд. Иако све ове мере можемо да добијемо и директно, згодно је да их једном функцијом добијемо све. Функција describe() то омогућава.

neto_zarada.vrednost.describe()
По свему судећи, расподела вредности из ове колоне није баш симетрична па би било добро да је визуелизујемо, тј. да прикажемо графички. Због тога смо на почетку учитавали библиотеку за цртање. Анализу података је, по правилу, лакше урадити ако "видимо" податке. Зато се нумеричка анализа и визуелизација података обично раде истовремено.
За визуелизацију једнодимензионалног скупа података (низа, листе или колоне у табели) најчешће се користи хистограм који нам приказује број елемената у одређеним интервалима, односно расподелу података. Хистограме цртамо помоћу функције hist(). Аргумент ове функције, сем низа чије бројеве хоћемо да прикажемо, јесте и опсег бројева у ком посматрамо хистограм са кораком (величином интервала). Помоћу функције axvline из библиотеке matplotlib.pyplot цртамо вертикалне линије одређене боје, дебљине и стила. Овде ћемо нацртати две вертикалне линије: наранџасту за медијану низа и белу за средњу вредност.
Приметите да смо функције median() и mean() преузели из numpy библиотеке.
y=neto_zarada.vrednost
y.hist(bins=range(35000,105000,4000))
plt.axvline(x=np.median(y), color='orange', linewidth=2, linestyle=":")
plt.axvline(x=np.mean(y), color='white', linewidth=2, linestyle="--")
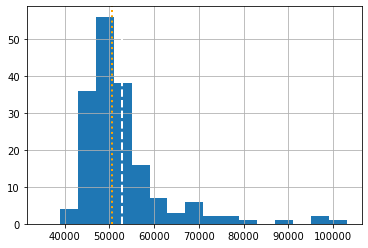
Слично, можемо да користимо функцију hist и из библиотеке за цртање. Разлике у начину приказивања нису велике.
plt.hist(y,bins=20)
plt.axvline(x=np.median(y), color='orange', linewidth=3, linestyle=":")
plt.axvline(x=np.mean(y), color='white', linewidth=2, linestyle="--")

Графичко приказивање расподеле података је, вероватно, најбољи начин да разумемо шта се у том скупу налази, да ли је расподела униформна или има "репове", где су тачке нагомилавања, да ли има "немогућих вредности" итд. Врло често је визуелизација податка део процеса чишћења података. Много је лакше уочити нелогичности у великом скупу података ако успемо да га добро прикажемо графички.
Пивотирање табеле¶
Табела коју смо на почетку учитали има 175 редова који се односе на било који индикатор. Ако исецамо само оне редове које нас у том тренутку интересују, изгубићемо све остале. Можда би било боље да трансформишемо табелу opps тако да по редовима буду општине, а по колонама индикатори. То се зове пивотирање табеле.
Заправо, узећемо и матични број и назив општине по редовима због контроле. Никад не знате да ли ће се у листи појавити две општине са истим именом, нпр. Палилула. Зато је добро да увек имамо и јединствени матични број. Та два назива колона ћемо ставити у листу и придружити аргументу index. Аргументу columns ћемо придружити све различите вредности које постоје у колони vrednost, а аргументу values ћемо придружити вредности из колоне која се баш тако зове, vrednost. Пивотирање табеле сада радимо помоћу функције pivot().
pivopps=opps.pivot(index=['idter','nter'], columns='Indikator', values='vrednost')
pivopps
Приметите како у табели нема оних колона IDIndikator, mes, god_ итд. Када смо "разапињали" пивот-табелу рекли смо шта хоћемо по редовима, а шта по колонама. Те заборављене колоне нисмо помињали. Нису нам сад ни потребне.
pivopps.columns
Сада можемо да променимо тип променљивих у табели. Један од начина да то урадимо је да наведемо тачно којим колонама хоћемо да променимо тип података и да наведемо који то тип треба да буде. Овде ћемо изабрати три колоне које ћемо убудуће третирати као нумеричке.
pivopps=pivopps.astype({'Број регистрованих незапослених ': 'float',
'Број становника - процена (последњи расположив податак за годину)': 'float',
'Просечна нето зарада за месец, према општини пребивалишта запослених': 'float'})
Пивот-табела нам даје вишедимензионални скуп података где анализа може да буде произвољно сложена. Ми се нећемо упуштати у анализу већ ћемо само дати примере два типа графичког приказа ових података. У једном примеру ћемо видети како изгледа зависност нумеричке вредности од категоријалне, а у другом нумеричке од нумеричке.
df=pivopps[['Степен развијености ЈЛС према Закону о регионалном развоју',
'Просечна нето зарада за месец, према општини пребивалишта запослених']]
Користећи библиотеку seaborn и функцију displot() пробаћемо да прикажемо мало сложенији, семитранспарентни хистограм где свака боја означава један од пет степени развијености јединице локалне самоуправе. Овде нећемо улазити у детаље функције и њене аргументе.
sns.displot(
data=df,
x="Просечна нето зарада за месец, према општини пребивалишта запослених",
hue="Степен развијености ЈЛС према Закону о регионалном развоју",
kind="hist",
aspect=1.8,
bins=15
)
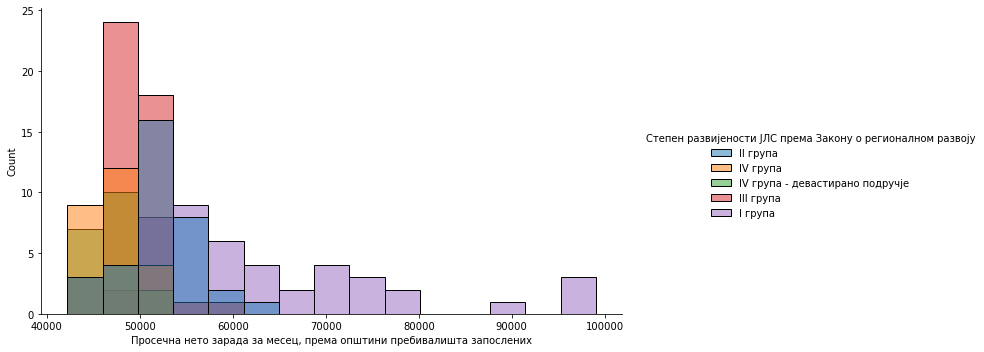
Оно што видимо са хистограма је да су општине са највећим приходом управо оне најразвијеније, а да у доњем делу ранг-листе има највише општина из треће групе. Такође, видимо и да редослед група у легенди није баш смислен. Пробајте то да средите самостално.
Користећи исту функцију, уместо пет хистограма који се преклапају можемо да нацртамо пет хистограма један поред другог. То ће можда бити прегледније.
sns.displot(
data=df,
x="Просечна нето зарада за месец, према општини пребивалишта запослених",
col="Степен развијености ЈЛС према Закону о регионалном развоју",
kind="hist",
aspect=1.4,
bins=20
)

Нема сумње да су слова на овом графикону превише мала, али то није нарочит проблем. Ови графикони су слика на html страни. Можемо ту слику да отворимо у новом табу браузера (десни клик на слику па Open Image in New Tab) да бисмо је после увећали и пажљиво проучили. Даље сређивање и анализу ових слика препуштамо вама.
Други начин приказа који смо овде хтели да демонстрирамо је обичан scatter plot. Примера ради, приказаћемо помоћу функције replot() у каквој су вези просечна зарада и проценат незапослених у општини. Податак о проценту незапослених немамо. Мораћемо прво да га израчунамо.
pivopps['Проценат незапослених']=pivopps['Број регистрованих незапослених ']/pivopps['Број становника - процена (последњи расположив податак за годину)']
sns.relplot(x="Просечна нето зарада за месец, према општини пребивалишта запослених",
y="Проценат незапослених",
hue="Степен развијености ЈЛС према Закону о регионалном развоју",
data=pivopps);
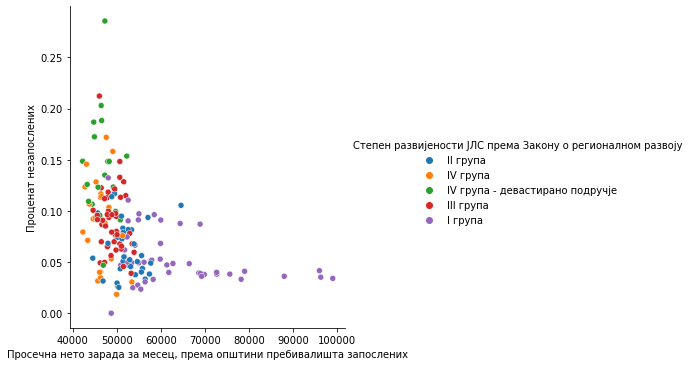
Овај графикон изгледа прилично убедљиво. Јасно видимо каква је веза између зарада и броја незапослених и како она изгледа по степену развијености општина. Даљу анализу препуштамо вама.
Приказ података на мапи¶
Многи подаци које имамо у табелама представљају гео-податке, односно податке у вези са разним топонимима, нпр. државама, општинама или локацијама. То нам омогућава да одређене податке придружимо гео-локацијама и представимо их на мапи. Тај тип представљања података захтева посебну библиотеку geopandas коју морамо посебно да инсталирамо и то није сасвим једноставно. Свеједно, претпоставићемо да је тај проблем успешно решен и идемо даље.
import geopandas as gpd
Фајл који нам је неопходан за приказивање мапа је колекција контура разних области. Те контуре су дате као низови тачака, односно полигони. У табелу коју смо преузели са сајта Републичког геодетског завода за сваку општину имамо податке о полигонима у два формата: wkt и geometry.
konture=gpd.read_file('data/opstina.csv', encoding='UTF-8')
konture.head(2)
Уколико DataFrame садржи колону geometry са полигонима, Пајтон ће помоћу функције plot() знати да их исцрта чак и без икаквих аргумената. Овако изгледају контуре свих 197 општина у Србији.
konture.plot()
Приметите да координате на мапи не одговарају степенима географске дужине и ширине. Разлог за то је што се у геодезији више користе UTM координате. Ко хоће може да изврши конверзију ових података, али нама сада то није потребно. Хоћемо само мапу.
Сад треба да повежемо две табеле: ону са просечним зарадама по општинама neto_zarada и ову са контурама општина konture. Ако пажљиво погледате називи општина нису исти у првој и другој табели. У првој, на пример, пише "Александровац", док у другој имамо "АЛЕКСАНДРОВАЦ" и "ALEKSANDROVAC". То би отежало повезивање да, срећом, нисмо сачували матичне бројеве општина. У првој табели то је била idter колона, а у другој је то opstina_maticni_broj. Помоћу функције rename() преименоваћемо назив колоне у обе табеле у MBO и конвертовати податке у тип integer уколико то нисмо већ урадили.
konture=konture.rename(columns={'opstina_maticni_broj':'MBO'})
konture['MBO']=konture['MBO'].astype(int)
neto_zarada=neto_zarada.rename(columns={'idter':'MBO'})
Повезивање две табеле ћемо урадити помоћу функције merge() по колони MBO.
konture2 = pd.merge(konture,neto_zarada,on='MBO')
konture2.head(2)
Сада би за сваку општину у табели требало да имамо и податке о заради и контуре. Остало је још само да то прикажемо на мапи.
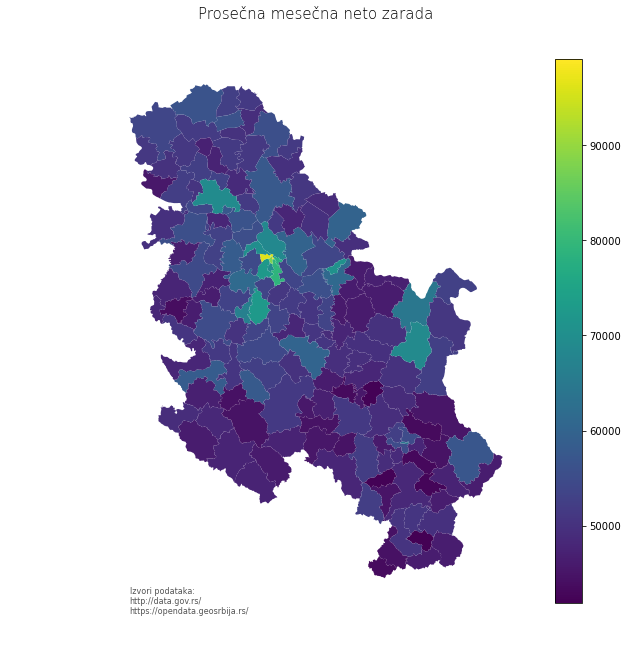
konture2.plot(column='vrednost')
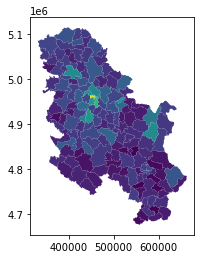
Када пажљиво погледате мапу, видећете да подаци за општине на Косову и Метохији нису приказани. Табела општина са контурама има 197 редова, а табела са подацима о зарадама 175. Републички завод за статистику у својим извештајима нема месечне показатеље за КиМ. Због тога је спојена табела краћа за та 24 реда. Имајте у виду да званични подаци различитих државних органа могу да се разликују по овом питању.
Што се естетике мапе тиче, исту мапу можемо да прикажемо и са нешто више детаља, легендом, насловом итд. У наредној ћелији је пример како то може да се уради. Слободно варирајте параметре и изаберите мапу која се вама највише свиђа.
konture2.plot(column='vrednost', legend=True, figsize=(12, 10))
plt.axis('off')
plt.title('Prosečna mesečna neto zarada\n\n', fontdict={'fontsize': '15', 'fontweight': '1'})
plt.annotate('Izvori podataka: \nhttp://data.gov.rs/\nhttps://opendata.geosrbija.rs/',
xy=(0.15, 0.10), xycoords='figure fraction', horizontalalignment='left', verticalalignment='top',
fontsize=8, color='#555555');