7. Индексирање и транспоновање табеле¶
У овој лекцији ћемо говорити о:
- индексирању табеле ради флексибилнијег приступа елементима табеле;
- приступу врстама и појединачним локацијама индексиране табеле;
- рачунању са целим редовима и колонама табеле; и
- транспоновању табеле.
7.1. Индексирање¶
Видели смо да је рад са колонама табеле веома једноставан.
Да бисмо могли да радимо са редовима табеле треба прво да нађемо једну колону чија вредност једнозначно одређује цео ред табеле. На пример, у табели са прошлог часа
| Ime | Pol | Starost | Masa | Visina |
|---|---|---|---|---|
| Ana | ž | 13 | 46 | 160 |
| Bojan | m | 14 | 52 | 165 |
| Vlada | m | 13 | 47 | 157 |
| Gordana | ž | 15 | 54 | 165 |
| Dejan | m | 15 | 56 | 163 |
| Đorđe | m | 13 | 45 | 159 |
| Elena | ž | 14 | 49 | 161 |
| Žaklina | ž | 15 | 52 | 164 |
| Zoran | m | 15 | 57 | 167 |
| Ivana | ž | 13 | 45 | 158 |
| Jasna | ž | 14 | 51 | 162 |
колона "Ime" је таква колона (колона "Visina" није погодна јер имамо двоје деце са висином 165, па када кажемо "дете са висином 165" није јасно о коме се ради; исто тако ни колоне "Pol", "Starost" и "Masa" нису погодне).
Таква колона се зове кључ јер је она кључна за приступање редовима табеле. Ако желимо да приступамо елементима табеле по редовима, морамо систему да пријавимо коју колону ћемо користити као кључ. То се постиже позивом функције set_index којој проследимо име колоне, а она врати нову табелу "индексирану по датом кључу":
import pandas as pd
podaci = [["Ana", "ž", 13, 46, 160],
["Bojan", "m", 14, 52, 165],
["Vlada", "m", 13, 47, 157],
["Gordana", "ž", 15, 54, 165],
["Dejan", "m", 15, 56, 163],
["Đorđe", "m", 13, 45, 159],
["Elena", "ž", 14, 49, 161],
["Žaklina", "ž", 15, 52, 164],
["Zoran", "m", 15, 57, 167],
["Ivana", "ž", 13, 45, 158],
["Jasna", "ž", 14, 51, 162]]
tabela = pd.DataFrame(podaci)
tabela.columns=["Ime", "Pol", "Starost", "Masa", "Visina"]
tabela1=tabela.set_index("Ime")
Нова табела (tabela1) се од старе (tabela) разликује само по томе што редови више нису индексирани бројевима (0, 1, 2, ...) већ именима деце (Ana, Bojan, Vlada, ...). Ево старе (неиндексиране табеле) која има колону "Ime" и чији редови су индексирани бројевима:
tabela
А ево и нове табеле у којој су редови индексирани именима деце:
tabela1
Колона "Ime" је и даље присутна у табели tabela1, али има посебан статус. Ако покушамо да јој приступимо као "обичној" колони добићемо грешку:
tabela1["Ime"]
Међутим, она је ту као индексна колона:
tabela1.index
Ако желимо да прикажемо висину деце у групи графиконом тако да имена деце буду на хоризонталној оси, то сада можемо урадити овако:
import matplotlib.pyplot as plt
plt.figure(figsize=(10,5))
plt.bar(tabela1.index, tabela1["Visina"])
plt.title("Visina dece u grupi")
plt.show()
plt.close()

Ознаке на хоризонталној оси узимамо из индексне колоне tabela1.index, док податке о висини стубића узимамо из колоне tabela1["Visina"].
7.2. Приступ врстама и појединачним ћелијама индексиране табеле¶
Структура података DataFrame је оптимизована за рад са колонама табеле. Срећом, када имамо индексирану табелу као што је то tabela1, користећи функцију loc (од енгл. location што значи "локација, положај, место") можемо да приступамо редовима табеле, као и појединачним ћелијама табеле.
Податке о појединачним редовима табеле можемо да видимо овако:
tabela1.loc["Dejan"]
Као аргумент функције loc можемо да наведемо и распон, и тако ћемо добити одговарајући део табеле:
tabela1.loc["Dejan":"Zoran"]
Ако као други аргумент функције loc наведемо име колоне, рецимо овако:
tabela1.loc["Dejan", "Visina"]
добићемо информацију о Дејановој висини.
tabela1.loc["Dejan", "Visina"]
Ево како можемо да добијемо информацију о маси и висини неколико деце:
tabela1.loc["Dejan":"Zoran", "Masa":"Visina"]
7.3. Рачун по врстама и колонама табеле¶
Кренимо од једног примера. У ћелији испод дате су оцене неких ученика из информатике, енглеског, математике, физике, хемије и ликовног:
razred = [["Ana", 5, 3, 5, 2, 4, 5],
["Bojan", 5, 5, 5, 5, 5, 5],
["Vlada", 4, 5, 3, 4, 5, 4],
["Gordana", 5, 5, 5, 5, 5, 5],
["Dejan", 3, 4, 2, 3, 3, 4],
["Đorđe", 4, 5, 3, 4, 5, 4],
["Elena", 3, 3, 3, 4, 2, 3],
["Žaklina", 5, 5, 4, 5, 4, 5],
["Zoran", 4, 5, 4, 4, 3, 5],
["Ivana", 2, 2, 2, 2, 2, 5],
["Jasna", 3, 4, 5, 4, 5, 5]]
Сада ћемо од ових података направити табелу чије колоне ће се звати "Ime", "Informatika", "Engleski", "Matematika", "Fizika", "Hemija", "Likovno" и која ће бити индексирана по колони "Ime":
ocene = pd.DataFrame(razred)
ocene.columns=["Ime", "Informatika", "Engleski", "Matematika", "Fizika", "Hemija", "Likovno"]
ocene1 = ocene.set_index("Ime")
ocene1
Ако желимо да израчунамо просек по предметима, треба на сваку колону ове табеле да применимо функцију mean. Листа са именима свих колона табеле ocene1 се добија као ocene1.columns, па сада само треба да прођемо кроз ову листу и за сваку колону да израчунамо просек:
for predmet in ocene1.columns:
print(predmet, "->", round(ocene1[predmet].mean(), 2))
Да бисмо израчунали просечне оцене сваког ученика функцију mean ћемо применити на врсте табеле које добијамо позивом функције loc. Погледајмо, прво, како то можемо да урадимо за једног ученика:
print("Đorđe ima sledeće ocene:")
print(ocene1.loc["Đorđe"])
print("Prosek njegovih ocena je:", round(ocene1.loc["Đorđe"].mean(), 2))
Списак свих ученика се налази у индексној колони, па просеке по свим ученицима можемо да израчунамо овако:
for ucenik in ocene1.index:
print(ucenik, "->", round(ocene1.loc[ucenik].mean(), 2))
7.4. Транспоновање табеле¶
Замена врста и колона табеле се зове транспоновање. Приликом транспоновања имена колона полазне табеле постају индекси нове табеле, док индексна колона полазне табеле одређује имена колона нове табеле:
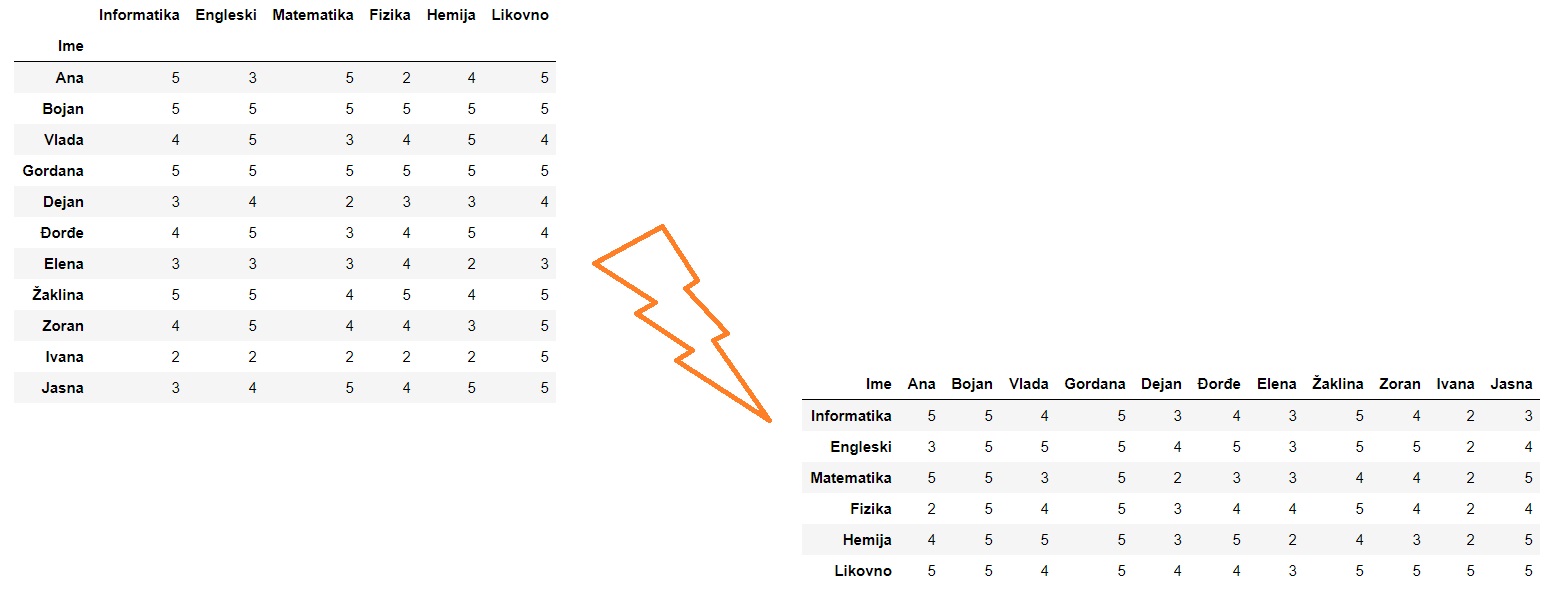
Транспоновање се често користи када табела има мало веома дугачких редова, па је у неким ситуацијама лакше посматрати транспоновану табелу која онда има пуно релативно кратких редова. Функције head и tail нам тада омогућују да се брзо упознамо са почетком и крајем табеле и да стекнемо неку интуицију о томе како табела изгледа.
Важно је рећи и то да се са табелама може радити и без транспоновања, јер све што можемо да урадимо на колонама табеле можемо да урадимо и на врстама. И поред тога, транспоновање се често користи јер је библиотека pandas оптимизована за рад по колонама табеле.
Табела се транспонује тако што се на њу примени функција Т која као резултат враћа нову, транспоновану табелу.
Ево примера са оценама:
ocene1
Транспоновану табелу добијамо овако:
ocene2 = ocene1.T
ocene2
Хајде још да се уверимо да су врсте и колоне замениле места и у пољима index и columns. У полазној табели је:
ocene1.index
ocene1.columns
А у транспонованој табели је:
ocene2.index
ocene2.columns
Како смо раније већ видели, просек оцена по предметима добијамо лако:
for predmet in ocene1.columns:
print(predmet, "->", round(ocene1[predmet].mean(), 2))
Да бисмо добили просек оцена по ученицима, можемо да приступимо врстама табеле користећи функцију loc како смо то већ видели, али можемо и да употребимо транспоновану табелу (рачунање просека по колонама, јер су колоне транспоноване табеле заправо врсте полазне табеле):
for ucenik in ocene2.columns:
print(ucenik, "->", round(ocene2[ucenik].mean(), 2))
7.5. Задаци¶
Задатке реши у Џупитеру.
Задатак 1. Пажљиво погледај овај Пајтон програм па одговори на питања која следе:
import pandas as pd
podaci = [["Ana", "ž", 13, 46, 160],
["Bojan", "m", 14, 52, 165],
["Vlada", "m", 13, 47, 157],
["Gordana", "ž", 15, 54, 165],
["Dejan", "m", 15, 56, 163],
["Đorđe", "m", 13, 45, 159],
["Elena", "ž", 14, 49, 161],
["Žaklina", "ž", 15, 52, 164],
["Zoran", "m", 15, 57, 167],
["Ivana", "ž", 13, 45, 158],
["Jasna", "ž", 14, 51, 162]]
tabela = pd.DataFrame(podaci)
tabela.columns=["Ime", "Pol", "Starost", "Masa", "Visina"]
tabela1=tabela.set_index("Ime")
temp_anomalije = pd.read_csv("podaci/TemperaturneAnomalije.csv", header=None)
temp_anomalije1 = temp_anomalije.T
temp_anomalije1.columns = ["Година", "Аномалија"]
- У чему је разлика између табела
tabelaиtabela1? - Шта представља израз
tabela1.index? - Шта је вредност израза
tabela1.loc["Ђорђе"]? - Шта је вредност израза
tabela1.loc["Ђорђе", "Висина"]? - Шта је вредност израза
tabela.loc["Ђорђе", "Висина"]? - Зашто смо на табелу
temp_anomalijeприменили функцијуT? - Колико колона има табела
temp_anomalije1?
Задатак 2. Ево трошкова живота једне породице током једне године, по месецима (сви износи су представљени у динарима):
| Stavka | Jan | Feb | Mar | Apr | Maj | Jun | Jul | Avg | Sep | Okt | Nov | Dec |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Stanarina | 8.251 | 8.436 | 8.524 | 8.388 | 8.241 | 8.196 | 8.004 | 7.996 | 7.991 | 8.015 | 8.353 | 8.456 |
| Struja | 4.321 | 4.530 | 4.115 | 3.990 | 3.985 | 3.726 | 3.351 | 3.289 | 3.295 | 3.485 | 3.826 | 3.834 |
| Telefon (fiksni) | 1.425 | 1.538 | 1.623 | 1.489 | 1.521 | 1.485 | 1.491 | 1.399 | 1.467 | 1.531 | 1.410 | 1.385 |
| Telefon (mobilni) | 2.181 | 2.235 | 2.073 | 1.951 | 1.989 | 1.945 | 3.017 | 2.638 | 2.171 | 1.831 | 1.926 | 1.833 |
| TV i internet | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 | 2.399 |
| Prevoz | 1.830 | 1.830 | 1.830 | 1.830 | 1.950 | 1.950 | 1.450 | 1.450 | 1.950 | 1.950 | 2.050 | 2.050 |
| Hrana | 23.250 | 23.780 | 24.019 | 24.117 | 24.389 | 24.571 | 24.736 | 24.951 | 25.111 | 25.389 | 25.531 | 25.923 |
| Ostalo | 4.500 | 3.700 | 5.100 | 3.500 | 2.750 | 4.250 | 7.320 | 8.250 | 3.270 | 4.290 | 3.200 | 8.390 |
У ћелији испод су исти подаци представљени листом:
troskovi = [
["Stanarina", 8251, 8436, 8524, 8388, 8241, 8196, 8004, 7996, 7991, 8015, 8353, 8456],
["Struja", 4321, 4530, 4115, 3990, 3985, 3726, 3351, 3289, 3295, 3485, 3826, 3834],
["Telefon (fiksni)", 1425, 1538, 1623, 1489, 1521, 1485, 1491, 1399, 1467, 1531, 1410, 1385],
["Telefon (mobilni)", 2181, 2235, 2073, 1951, 1989, 1945, 3017, 2638, 2171, 1831, 1926, 1833],
["TV i internet", 2399, 2399, 2399, 2399, 2399, 2399, 2399, 2399, 2399, 2399, 2399, 2399 ],
["Prevoz", 1830, 1830, 1830, 1830, 1950, 1950, 1450, 1450, 1950, 1950, 2050, 2050],
["Hrana", 23250, 23780, 24019, 24117, 24389, 24571, 24736, 24951, 25111, 25389, 25531, 25923],
["Ostalo", 4500, 3700, 5100, 3500, 2750, 4250, 7320, 8250, 3270, 4290, 3200, 8390]
]
(а) Представи табелу структуром DataFrame. Индексирај табелу.
(б) Израчунај и испиши просечну потрошњу ове породице по ставкама (колико је породица просечно потрошила на станарину, колико на струју, итд).
Задатак 3. Ученици осмог разреда једне школе су анкетирани о томе коју врсту филмова најрадије гледају. Подаци анкете су дати у следећој табели (у коју нису унети неважећи и бесмислени одговори):
| Žanr | 8-1 | 8-2 | 8-3 | 8-4 | 8-5 |
|---|---|---|---|---|---|
| Komedija | 4 | 3 | 5 | 2 | 3 |
| Horor | 1 | 0 | 2 | 1 | 6 |
| Naučna fantastika | 10 | 7 | 9 | 8 | 9 |
| Avanture | 4 | 3 | 4 | 2 | 2 |
| Istorijski | 1 | 0 | 2 | 0 | 0 |
| Romantični | 11 | 10 | 7 | 9 | 8 |
(а) Формирај одговарајућу табелу позивом функције DataFrame. Индексирај табелу колоном "Žanr".
(б) Израчунај и испиши колико гласова је добио сваки од наведених жанрова.
(в) За свако одељење израчунај и испиши колико је било валидних гласова.
(г) Колико је укупно ученика осмих разреда учествовало у анкетирању? (Рачунамо само ученике који су дали валидне одговоре на анкету.)
Задатак 4. Нутритивни подаци за неке намирнице су дати у следећој табели:
| Namirnica (100g) | Energetska vrednost (kcal) | Ugljeni hidrati (g) | Belančevine (g) | Masti (g) |
|---|---|---|---|---|
| Crni hleb | 250 | 48,2 | 8,4 | 1,0 |
| Beli hleb | 280 | 57,5 | 6,8 | 0,5 |
| Kisela pavlaka (10% m.m.) | 127 | 4,0 | 3,1 | 10,5 |
| Margarin | 532 | 4,6 | 3,2 | 1,5 |
| Jogurt | 48 | 4,7 | 4,0 | 3,3 |
| Mleko (2,8% m.m.) | 57 | 4,7 | 3,3 | 2,8 |
| Salama parizer | 523 | 1,0 | 17,0 | 47,0 |
| Pršuta | 268 | 0,0 | 25,5 | 18,4 |
| Pileća prsa | 110 | 0,0 | 23,1 | 1,2 |
У ћелији испод ови подаци су припремљени у облику индексиране DataFrame структуре (са скраћеним именима):
namirnice = pd.DataFrame([
["Chleb", 250, 48.2, 8.4, 1.0],
["Bhleb", 280, 57.5, 6.8, 0.5],
["Pavlaka", 127, 4.0, 3.1, 10.5],
["Margarin", 532, 4.6, 3.2, 1.5],
["Jogurt", 48, 4.7, 4.0, 3.3],
["Mleko", 57, 4.7, 3.3, 2.8],
["Parizer", 523, 1.0, 17.0, 47.0],
["Pršuta", 268, 0.0, 25.5, 18.4],
["PilPrsa", 110, 0.0, 23.1, 1.2]])
namirnice.columns=["Namirnica", "EnergVr", "UH", "Bel", "Masti"]
namirnice1 = namirnice.set_index("Namirnica")
(а) Милош је за доручак појео два парчета белог хлеба и попио шољу млека. Свако парче хлеба је било намазано павлаком и имало је један шнит пршуте. Колика је енергетска вредност Милошевог доручка (у kcal), ако претпоставимо да једно парче хлеба има 100 г, да је за мазање једног парчета хлеба довољно 10 г премаза, да један шнит пршуте има 20г и да шоља млека има 2 дл (што је приближно 200 г)?
(б) Колико грама масти је било у Милошевом доручку?
(в) Прикажи дијаграмом количину угљених хидрата у намирницама наведеним у табели.
Задатак 5. У фолдеру podaci се налази датотека TemperaturneAnomalije.csv која садржи податке о томе за колико степени Целзијуса је средња измерена температура на Земљи већа од оптималне у последњих 40 година. Ова табела има два дугачка реда који изгледају овако:
1977,1978,1979,1980,1981,...
0.22,0.14,0.15,0.3,0.37,...
У првом реду се налазе године (1977-2017), а у другом измерена температурна аномалија. Табела нема заглавље.
(а) Учитај табелу у структуру DataFrame користећи функцију read_csv из библиотеке pandas. (Напомена: када табела нема заглавље у функцији за учитавање треба навести опцију header=None.)
(б) Транспонуј табелу и колоне транспоноване табеле назови "Godina" i "Anomalija".
(в) Индексирај табелу колоном "Godina".
(г) Прикажи температурне аномалије дијаграмом.
Задатак 6. У фолдеру podaci се налази датотека StanovnistvoSrbije2017.csv (која има заглавље). Табела има три колоне које се зову "Starost", "M" и "Ž".
(а) Учитај датотеку у структуру података DataFrame и индексирај табелу колоном "Starost".
(б) Прикажи процењени број мушкараца и жена по старости линијским дијаграмом.
(в) На основу података из табеле израчунај колики је процењени број становника у следећим старосним групама:
- 0--17 година,
- 18--65 година, и
- 66 и више година,
и представи ова три податка секторским дијаграмом. (Упутство: следећи израз може бити од помоћи: tabela.loc["0":"17", "M":"Ž"])
Задатак 7. У табели испод су дати подаци о продаји неких производа у пет пословних јединица једне компаније (бројеви представљају број продатих комада у једном месецу):
| Proizvod | PJ1 | PJ2 | PJ3 | PJ4 | PJ5 |
|---|---|---|---|---|---|
| Cipele | 5 | 17 | 3 | 11 | 9 |
| Košulja | 8 | 6 | 7 | 4 | 0 |
| Kaiš | 4 | 1 | 3 | 5 | 1 |
| Pantalone | 4 | 2 | 6 | 4 | 5 |
| Čarape (par) | 8 | 9 | 7 | 4 | 9 |
| Kravata | 1 | 0 | 3 | 2 | 4 |
Следећа табела садржи цене ових производа у динарима:
| Proizvod | Cena (din) |
|---|---|
| Cipele | 11.250 |
| Košulja | 6.500 |
| Kaiš | 4.750 |
| Pantalone | 2.500 |
| Čarape (par) | 750 |
| Kravata | 3.500 |
Ћелија испод садржи податке из ове две табеле представљене у облику листе:
proizvodi = [
["Cipele", 5, 17, 3, 11, 9],
["Košulja", 8, 6, 7, 4, 0],
["Kaiš", 4, 1, 3, 5, 1],
["Pantalone", 4, 2, 6, 4, 5],
["Čarape (par)", 8, 9, 7, 4, 9],
["Kravata", 1, 0, 3, 2, 4]]
cene = [
["Cipele", 11250],
["Košulja", 6500],
["Kaiš", 4750],
["Pantalone", 2500],
["Čarape (par)", 750],
["Kravata", 3500]]
(а) Представи обе табеле структуром DataFrame. Индексирај обе табеле.
(б) Израчунај колико је укупно у том месецу продато ципела, кошуља, каишева, панталона, чарапа и кравата.
(в) Израчунај колико је у том месецу компанија зарадила на продаји ципела, колико на продаји кошуља, колико на продаји каишева, итд.
(г*) Израчунај и испиши зараду сваке пословне јединице у том месецу.