Sadržaj
Увод
Интернет ствари и паметни градови
Вештачка интелигенција
Мaшинско учење
Обрада великих количина података
Роботика
Криптографија
Квантни рачунари
Закључак
Шта је машинско учење¶
Начини задавања проблема¶
Када неки проблем желимо да решимо помоћу рачунара, најпре је потребно да тај проблем на неки начин опишемо (прецизирамо, задамо). Код једноставнијих проблема уобичајено је да се прецизно формулише на који начин излаз зависи од улаза, а затим да се на основу те формулације напише програм који решава проблем. На пример, програм који приказује текст лако може да одреди ширине појединих речи у приказу и да израчуна када треба да пређе у нови ред. За рачунар је ово лако јер код оваквих проблема човек може да формулише прецизна правила и угради их у програм. Слично томе, за рачунар је лако да израчуна укупна издвајања једног предузећа на плате и обавезне доприносе, када су познате плате свих запослених и прописи за рачунање доприноса, који могу директно да се уграде у програм. За овакве проблеме кажемо да су задати експлицитно. Међутим, овај приступ код неких проблема није практичан, јер правила могу да буду компликована и са много изузетака, а често није ни могућ. Замислимо, на пример, да нам је потребан програм који разврстава (класификује) фотографије животиња према врсти животиње приказане на фотографији. Такав програм треба, полазећи од неколико стотина хиљада бројева који представљају слику, да израчуна одговор облика „Ово је пас“, „Ово је мачка“, „Ово је коњ“ и слично. Задатке овог типа сматрамо тешким за решавање помоћу рачунара, јер нисмо у стању да начин на који ми то радимо искажемо кроз прецизна правила, која би могла директно да се уграде у програм.

Како рачунару описати поступак израчунавања врсте животиње, само на основу RGB вредности пиксела који чине слику те животиње? (овде је приказан само увећан детаљ слике).¶
Оно што можемо да урадимо у оваквим проблемима је да задатак опишемо помоћу великог броја примера, тј. имплицитно. У овом случају то би значило да рачунару за сваку врсту животиње која може да се појави као одговор, дамо велики број (нпр. неколико хиљада) слика те животиње.
Разврставање слика животиња је узето као само један неутралан и популаран пример, иако не делује као нарочито важан задатак. Сетимо се зато и неколико сличних проблема чије решавање има већи практичан значај, као што је препознавање људи на основу фотографије лица, или препознавање обољења органа на медицинским снимцима. Поред поменутих и многих других проблема рачунарског вида, постоји још мноштво најразличитијих проблема који су врло незгодни за формално описивање. Знамо, на пример, да постоје програми који омогућавају рачунарима и мобилним телефонима да „разумеју“ људски говор, односно да га конвертују у текст, да га анализирају и закључе какву акцију треба да предузму. Улаз за овакве програме је аудио запис говора, који се у основи састоји од различитих јачина и фреквенција звука забележених у врло кратким и честим временским интервалима. Јасно је да ни у овом случају нисмо у стању да директно формулишемо правила, помоћу којих би се на основу тих јачина и фреквенција звука израчунало значење изговорене реченице.

Поступак израчунавања значења реченице на основу њеног¶
Аудио записа је практично немогуће задати експлицитно.
Проверите да ли међу проблемима који се решавају помоћу рачунара можете да разликујете оне које умемо у потпуности да задамо експлицитно, од оних за које то нисмо у стању да урадимо.

- Програм који управља лансирањем ракете у свемир.
- Програм који управља аутомобилом током вожње.
- Програм за вођење евиденције пословања.
- Програм који игра шах боље од светског првака.
Q-14: За које од набројаних програма је човек у стању да у потпуности експлицитно опише проблем?

Можете ли да набројите још неке проблеме који се задају експлицитно и неке који се задају имплицитно?
Како рачунар решава имплицитно задате проблеме¶
Човек најчешће учи управо из многобројних примера, а тек након учења је у стању (и то не увек) да стечено знање искаже формално, кроз разна правила, дефиниције, логичке услове, једначине и слично. Ово у принципу важи и за сваког човека појединачно, и за људски род у целини. Сви смо, на пример, прво научили да просто препознајемо поједине животиње кад их угледамо, а тек знатно касније је разрађен систем детаљног описивања разлика између одређених сличних врста и формулисана су правила, тј. кључеви за класификацију. Они који се данас определе за изучавање тих прецизних поступака, пре тога су увелико научили да препознају животињске врсте не користећи никаква посебна правила (мада не толико прецизно, као уз помоћ правила). Слично томе, прво смо научили да говоримо просто слушајући говор, а касније смо створили разне лингвистичке дисциплине потребне за прецизно описивање структуре и функције говора (фонологија, морфологија, лексика, семантика, прагматика и друге).
Ситуација са рачунарима је сасвим другачија. Њима су неопходна правила да би могли нешто да науче. Они не могу да граде осећај или интуицију онако како то ради човек. Све сложене операције које данашњи рачунари обављају, на крају се своде на рачунање великом брзином. Зато, када је потребно да рачунар на основу примера научи да решава неки проблем, он у ствари покушава да израчуна правила, на основу којих ће касније да рачуна одговоре на питања која му постављамо.
Сада је још мало јасније зашто је за решавање проблема помоћу рачунара експлицитан опис проблема много погоднији него имплицитан. Код експлицитно описаних проблема правила за израчунавање одговора су нам позната, па проблем може да се решава директно, поузданим и разрађеним методама програмирања. Са друге стране, у имплицитно задатим проблемима правила за рачунање одговора тек треба открити, а питање је колико успешно и на који начин то може да се уради у сваком конкретном случају. Зато проблем описујемо имплицитно (примерима) само када не умемо да га опишемо експлицитно (правилима). У таквим, имплицитно описаним проблемима, настојимо да оспособимо рачунар да сам дође до правила за израчунавање одговора. Када располаже само примерима, рачунар може да формира потребна правила једино на основу тих примера, тј. тако да формирана правила дају добар одговор у што већем броју доступних примера. Машине за сада могу да уче искључиво на овај начин, у оквиру кога су могући различити приступи, од којих ћемо неке поменути у наставку.
Укратко, потреба за „учењем“ код рачунара се јавља само када је проблем задат имплицитно, а у том случају општи принцип је да се кроз анализирање примера прво израчунају правила за даље израчунавање очекиваних одговора. Тиме долазимо до следеће дефиниције појма машинског учења.

Машинско учење je област вештачке интелигенције, која се бави решавањем проблема описаних помоћу примера. Предмет проучавања машинског учења су алгоритми, који кроз интензивну анализу великог броја података могу да препознају одређене правилности (обрасце) у тим подацима и на основу тога касније доносе одлуке без, или уз минималну људску интервенцију.
Процес машинског учења¶
Процес машинског учења одвија се у више фаза.
На самом почетку прецизирамо опсег проблема (енгл. problem scope), тј. што конкретније одређујемо шта спада у проблем који решавамо, а шта не. На пример, ако желимо да направимо програм који препознаје цифре 0-9 на основу њихових слика, пожељно је да прецизирамо да ли примери обухватају руком писане цифре, фонтове или и једно и друго, да ли користимо само ухваћене садржаје екрана (screen shots) или и фотографије бројева, границе у којима се креће резолуција слике коју програм треба да препозна итд.
Када се проблем прецизније зада, следи прикупљање и припрема података за учење. Нерелевантне и неисправне податке одбацујемо, а преостале податке прилагођавамо по формату уколико је потребно.
Када пречистимо и припремимо податке, потребно је да се боље упознамо са њиховим особинама и одлучимо на који начин ће ови подаци бити представљени систему за учење. Истина је да се изворни подаци, ма ког типа они били (слика, текст, аудио итд, као и разне комбинације типова), у рачунару већ памте у облику бројева. Међутим, начин на који се подаци стандардно кодирају не мора да буде и најпогоднији облик за учење. Потребно је, дакле, одредити нека нумеричка својства (енгл. features) датих података, којима ће ти подаци на погодан начин да буду представљени у систему за учење. Нумеричка својства која ће да представљају податке у систему за учење могу да се добију класичним алгоритмима за обраду слике, звука, текста итд.
Након трансформације изворних података у низове поменутих својстава (енгл. feature vectors), наступа следећа фаза, која је вероватно и најпознатија, а то је тренинг. У току те фазе систем нешто учи из доступних података. Зависно од вида машинског учења (види ниже), циљ учења може да буде проналажење сличног раније виђеног податка, проналажење категорије (класе) којој припада податак, избор најбољег понашања за ситуацију описану улазним податком и слично. Сваки систем за учење подразумева неки унапред утврђен алгоритам, који се након тренинга употребљава за добијање одговора. Том алгоритму недостају само одређени нумерички коефицијенти који су му потребни за израчунавање одговора, а који се одређују током тренинга. Задатак тренинга и јесте управо да генерише ове коефицијенте, који чине такозвани аналитички модел, или краће - модел.
По завршетку тренинга, добијени модел се тестира (евалуира), тј. проверава се колико су добри одговори које добијамо помоћу тог модела. Да би оцена квалитета била поузданија, приликом тестирања се користе нови улазни подаци, који нису били доступни програму за тренинг.
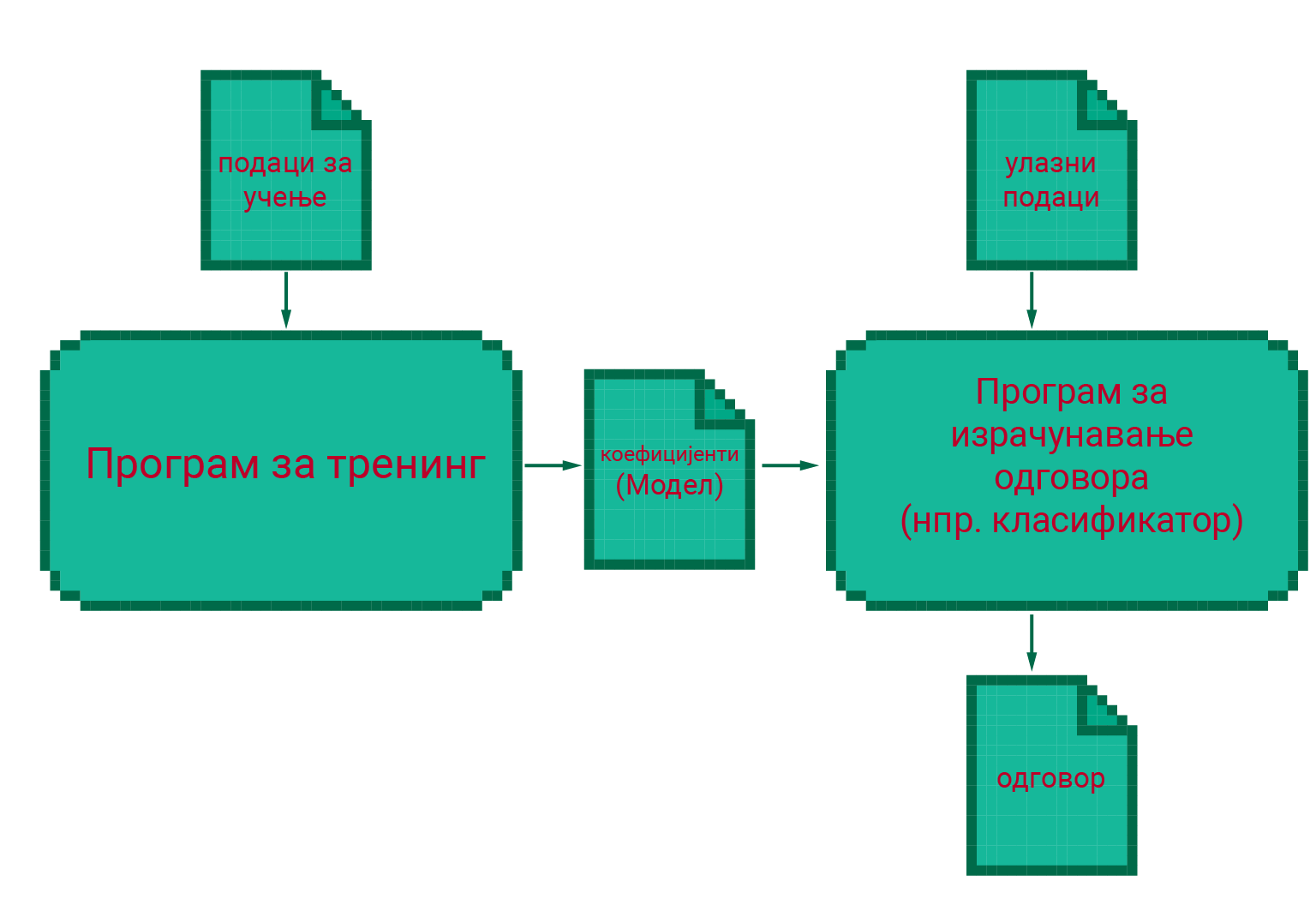
Процес учења¶
Тренинг система за машинско учење не треба схватати као једнократан посао, јер генерисани модел из разних разлога може да не буде довољно квалитетан. Зато је често након тестирања модела и детаљнијег испитивања његовог квалитета потребно да се промене нека подешавања тренинга, или да се скуп података за учење допуни или додатно прочисти, а затим да се тренинг покрене поново. Може да буде потребно да се ови кораци понове велики број пута док се не дође до модела задовољавајућег квалитета. Када се добије задовољавајући модел, наступа завршна фаза, а то је употреба модела (експлоатација), током које други програм користи генерисани модел, односно коефицијенте садржане у њему. Овај други програм решава полазни проблем тако што извршава онај раније помињани, унапред припремљен алгоритам над новим улазним подацима (сличним онима из скупа за тренинг), користећи у рачунању и коефицијенте из аналитичког модела.
Неке карактеристике машинског учења¶
Врста закључивања која се дешава у системима за машинско учење је индуктивно закључивање, од (многобројних) појединачних примера ка општим правилима. За ову врсту закључивања ни код људи нема гаранције да се применом закључака или изведених правила у сваком појединачном случају добија исправан, или најбољи одговор. Циљ је пре свега да се дође до правила које важи у што већем броју случајева. Тако се ни од система за машинско учење не очекује да буду у потпуности тачни, тј. да генеришу идеалан модел, тим пре што примери на којима систем учи могу да буду и делимично погрешни (да садрже шум), да не буду потпуно конзистентни (ни људски експерти се не слажу у свему у потпуности), или недовољно комплетни (да не покривају у потребној мери све значајне случајеве, тј. да нису репрезентативни). Због тога се и квалитет система за машинско учење, односно добијеног аналитичког модела оцењује само статистички. Већ смо поменули да се мера квалитета модела добија тестирањем на неком скупу података, који је по формату исти као и подаци за тренинг, али који није био доступан систему за учење током тренинга, тј. генерисања модела. Сад видимо да је због начина задавања и решавања проблема, статистички начин вредновања модела у ствари једино што нам је на располагању. Тако, квалитет модела често изражавамо у виду процентуалних учесталости прављења одређених врста грешака (ово зависи од вида учења о коме је реч).
Кључна улога тестирања модела је да се верификује да је тренинг обављен на задовољавајући начин, односно да укаже на могуће принципијелне пропусте током тренинга, или слаб општи квалитет. Као што смо поменули, принципијелни пропусти могу да се отклоне или ублаже другачијим подешавањем тренинга, или прочишћавањем и обогаћивањем скупа података за тренинг. Осим тога, тестирање може да послужи и за поређење више релативно квалитетних модела, тако да можемо да изаберемо најбољи расположиви модел и употребимо га у експлоатацији. Подаци за тренинг се у принципу стално прикупљају, па се и тренинзи над све већим и квалитетнијим скуповима података стално извршавају. Када се добије успешнији модел, претходни модел који је до тада експлоатисан се обично веома једноставно замењује новим, бољим. Наиме, модел се типично налази у једном бинарном фајлу, у формату специфичном за дати начин учења и дати проблем у коме се модел примењује. То значи да се замена модела своди на обичну замену једног фајла.