
Увод у пројекат
На тржишту постоји велики број апликација које се у мањој или већој мери ослањају на примену, анализу и обраду разговорног или књижевног језика. Са тим у вези, у пракси се јавља изазов осмишљања задовољавајућих алгоритам и структура података које би служиле том циљу. Кроз овај пројекат ученици би требало да прођу кроз неколико карактеристичних фаза: дизајнирање структура података, формирање речника и имплементирање алгоритама који би омогућили минималан скуп функционалности обраде језика.
Дефиниција проблема
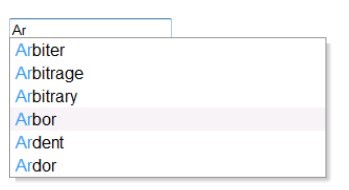
Потребно је направити апликацију која на основу једног или више извора (низ текстуалних датотека) формира речник датог језика и пружа основне функционалности. У основне функционалности спадају:
• Autocomplete - током самог уноса (од стране корисника) приказује речи из речника код којих се почетна слова поклапају са уносом.
• Провера да ли унета реч постоји у речнику
• Додавање речи у речник
• Did you mean - Претрага сличних речи и препорука у случају грешке
Као нешто формалнију дефиницију „сличних“ речи подразумевају се све речи које се разликују у одређеном броју слова од задате речи (потпуно је прихватљиво да у имплементацији овог пројекта то буде најједноставнији пример тј. једно слово разлике).
Формирање речника се заснива на пролазак кроз текстуалне датотеке (на пример неколико књига писаних на истом језику), разграничавање речи (уклањање знакова интерпукције, препознавање почетка и краја речи) и смештање свих препознатих речи у речник.
У имплементацији речника потребно је користити Trie стабла. Од ученика се очекује да проуче поменуту структуру и пре саме имплементације изађу са теоријским прегледом алгоритама који покривају функционалности. Потребно је омогућити смештање на диск (као и учитавање) тренутно активног речника. Програм треба да комуницира са корисником преко једноставног графичког интерфејса који пружа подршку за све релевантне делове апликације (формирање речника и основне функционалности).
Корисни линкови:
http://en.wikipedia.org/wiki/Trie
http://geekyisawesome.blogspot.com/2010/07/c-trie.html
http://nullwords.wordpress.com/2013/03/06/the-trie-data-structure-a-prefix-tree-for-autocompletes/